存储池 && PG及配置管理
命令拆解
Ceph 命令是"层级式"命名的,拆开看每个词就不需要死记:
ceph osd pool rm xixi xixi --yes-i-really-really-mean-it
│ │ │ │ │ │
│ │ │ │ │ └── "我真要这么干"池删除的最高级双重确认'两次 really'
│ │ │ │ └── 池名(要输两遍,防止手滑)
│ │ │ └── Remove 删除
│ │ └── 存储池(逻辑分区)
│ └── OSD 守护进程层
└── Ceph CLI 总入口
| 词 | 含义 | 记忆方法 |
|---|---|---|
ceph |
Ceph 集群 CLI 总入口 | 所有命令都从这个开始 |
osd |
Object Storage Daemon | 存储相关操作(池、PG、CRUSH 都归这层管) |
pool |
存储池,逻辑分区 | 数据的"命名空间",不同业务用不同池 |
pg |
Placement Group 归置组 | 数据分布的最小单位,一个 PG 里可放成千上万个对象 |
rm |
Remove 删除 | |
create |
创建 | |
get |
查单个属性 | 精确查询某个参数值 |
set |
修改属性 | 修改某个参数值 |
dump |
导出全部 | 导出所有配置/规则,常配合 grep 过滤 |
show |
查看最终生效配置 | 合并 Config DB + ceph.conf + 默认值 给出进程实际跑的配置 |
ls |
List 列出 | 列出所有池 / 规则 |
config |
集中化配置数据库 | 替代传统 ceph.conf,Monitor 集中存储 |
crush |
CRUSH 算法 / 拓扑表 | 集群的"地图"——数据该往哪放 |
application |
池用途声明 | 告诉集群这池是给 RBD / CephFS / RGW 用的 |
replicated |
副本池类型 | 数据完整复制多份——"一式三份" |
erasure |
纠删码池类型 | 切块 + 校验块——"拼图 + 备用块" |
pg_num |
PG 总数 | 池里有多少个"调度组" |
pgp_num |
参与数据放置的 PG 数 | 多少个调度组实际在干活,≤ pg_num |
size |
副本数 | 数据一共存几份 |
min_size |
最小副本数 | I/O 服务需要的最少可用副本数 |
nodelete |
池级删除锁 | 给某个池打上 true → 该池不可删除 |
mon_allow_pool_delete |
集群级删除开关 | Monitor 总闸,控制整个集群是否允许删池 |
pg_autoscale_mode |
PG 自动伸缩 | Ceph 根据 OSD 数量和用量自动调整 PG 数 |
global |
全局配置层 | 影响所有守护进程(mon/osd/mgr/mds/client) |
mon / osd / mgr |
类型级配置 target | 只影响某一类守护进程 |
osd.0 / mon.Ceph-201 |
实例级配置 target | 精确到某一个具体进程 |
--yes-i-really-really-mean-it |
"我真要这么干"(双重确认) | 删池的最高级确认,两个 really |
--force |
跳过普通确认 | 常规操作的安全确认 |
命令层级——越靠左越宏观,越靠右越具体:
ceph --> 集群层(管一切)
ceph osd --> OSD 层(管池、管 PG、管 CRUSH)
ceph osd pool --> 池层(管大小、管副本、管类型)
ceph config --> 配置层(管参数、管开关)
| 层面 | 命令入口 | 管的 | 视角 |
|---|---|---|---|
| OSD 数据层 | ceph osd ... |
CRUSH 地图、OSD 状态、池属性、PG 状态 | CRUSH 全局视角——"数据该往哪放" |
| 配置管理层 | ceph config ... |
集中化配置数据库、参数读写 | Monitor 视角——"集群怎么跑" |
| Dashboard 层 | ceph dashboard ... |
Web 管理界面、用户权限 | 图形化视角——"不想敲命令时用它" |
存储池概述
池(Pool)是个啥?
🧱 池是 Ceph 里存储数据的逻辑分区,你可以把它理解成一个"命名空间"
- 不同的业务(RBD 块存储、CephFS 文件系统、RGW 对象存储)各自用各自的池,井水不犯河水
| 池的核心作用 | 大白话解释 |
|---|---|
| 逻辑分区 | 给不同应用划地盘,互不干扰 |
| 数据保护 | 指定副本数或纠删码,决定数据能坏几块盘还不丢 |
| CRUSH 规则 | 绑一条 CRUSH 规则控制数据分布 比如限定故障域或 OSD 的 class 标签(ssd/hdd/nvme) |
| 访问控制 | 权限按池粒度划分 Monitor 发证,OSD 验票,限定谁能读写这个池 |
| 快照管理 | 对整个池做快照,出事了能回滚 |
数据存储流程对比
我们最熟悉的是副本池的流程(参考之前的笔记📚),先用它过一遍,再对照看纠删码池
🔹 副本池流程(复习)—— 以 3 副本为例:
┌──────────────────────────────────────────┐
│ Step 1:文件 → 切成固定 4MB 对象 │
│ │
│ 100MB 照片 │
│ │ │
│ ▼ │
│ ┌──────┐┌──────┐┌──────┐ ┌──────┐ │
│ │ 4MB ││ 4MB ││ 4MB │ ... │ 4MB │ │
│ │ obj1 ││ obj2 ││ obj3 │ ×25 │ obj25│ │
│ └──────┘└──────┘└──────┘ └──────┘ │
│ '每个对象固定 4MB,不够就补齐' │
└──────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Step 2:对象→Pool→命中某个 PG │
│ │
│ "对象名" + CRUSH Map ──→ PG.7 │
│ 'CRUSH①:决定对象归哪个 PG' │
└──────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Step 3:PG → CRUSH 再算 → 副本落盘 │
│ │
│ PG.7(size=3,要放 3 份) │
│ │ │
│ ▼ 'CRUSH②:决定副本落哪几块盘' │
│ │ │
│ ├─→ 副本① → osd.1(host A) │
│ ├─→ 副本② → osd.4(host B) │
│ └─→ 副本③ → osd.7(host C) │
│ ⚠️ (故障域 = host) │
│ obj1 的 3 个副本,落在 3 台不同主机上 │
│ '读的时候随便找一个副本就能拿到完整数据' │
└───────────────────────────────────────────┘
📌 副本池的本质:一份数据原样 copy 好几份,写的时候多写几遍,读的时候读最近的那份就行
🔹 纠删码池流程 —— 以 6+3 为例:
'前面两步一模一样,差异在第三步'
│
▼
┌──────────────────────────────────────────────┐
│ Step 3:PG → 编码切块 → 分散落盘 │
│ │
│ PG.7 收到 obj1(4MB 对象) │
│ │ │
│ ▼ '不是直接 copy,而是先编码' │
│ │ │
│ 把 4MB 对象切成 6 个数据块 │
│ │ │
│ ├─→ 数据块① │
│ ├─→ 数据块② │
│ ├─→ 数据块③ k = 6 个数据块 │
│ ├─→ 数据块④ │
│ ├─→ 数据块⑤ │
│ └─→ 数据块⑥ │
│ │ │
│ ▼ '根据 6 个数据块算出 3 个校验块' │
│ │ │
│ ├─→ 校验块⑦ │
│ ├─→ 校验块⑧ m = 3 个校验块 │
│ └─→ 校验块⑨ │
│ │ │
│ ▼ 'CRUSH②:9 个块分散到 9 块盘上' │
│ │ │
│ ├─→ 块① → osd.1 ├─→ 块⑥ → osd.6 │
│ ├─→ 块② → osd.2 ├─→ 块⑦ → osd.7 │
│ ├─→ 块③ → osd.3 ├─→ 块⑧ → osd.8 │
│ ├─→ 块④ → osd.4 ├─→ 块⑨ → osd.9 │
│ └─→ 块⑤ → osd.5 │
│ 总共 k+m = 9 个块,散落在 9 块不同的盘上 │
│ ⚠️ 如果故障域是 host → 需要 9 台主机! │
│ 如果故障域是 osd → 9 块盘可以都在同一台主机上 │
│ '只要任意 6 块还在,数据就能算回来' │
└──────────────────────────────────────────────┘
📌 纠删码池的本质:数据不存整份,而是切成块 + 算出校验块,散开到更多盘上
- 用 CPU + I/O 换空间
- 具体差多少?往下看对比表格
🔹 读写路径对比 —— 关键差异一目了然:
🌰写路径:
副本池(3副本) 纠删码池(6+3)
obj1 ──→ copy 3 份 obj1 ──→ 切成6块+算3块
│ │
▼ ▼
直接写 3 块盘 编码后写 9 块盘
'写 3 次,简单粗暴' 'CPU 编码开销 + 写 9 次 I/O'
│ │
写放大:3x 写放大:1.5x
'4MB 对象占 12MB 磁盘' '4MB 对象只占 6MB 磁盘'
=====================================================
🌰读路径:
副本池(3副本) 纠删码池(6+3)
需要数据 ──→ 读最近的 1 个副本 需要数据 ──→ 读任意 6 块
│ │
▼ ▼
拿到完整数据 CPU 解码拼回数据
'读 1 次,秒返回' '读 6 次 I/O + CPU 解码'
│ │
延迟:低 延迟:高
存储池的两种类型
| 类型 | 英文名称 | 原理 | 类比 |
|---|---|---|---|
| 副本池 | replicated | 数据完整复制多份,每个副本放在不同 OSD 上 | RAID1(多副本) |
| 纠删码池 | erasure | 数据切成 k 个数据块 + 算出 m 个校验块 共 k+m 个块,散落在不同盘上 |
RAID5(校验码) |
通俗解释:
- 副本池就是"一式三份"——同一份数据 copy 到三块盘上,简单粗暴,坏两块盘都不怕
- 缺点是废空间,3 副本 = 实际可用只有 1/3 的容量
- 纠删码池像"拼图+备用块"——把数据切成 6 个数据块,再算 3 个校验块,总共 9 个块散落在 9 块盘上
- 只要任意 6 块还在就能恢复完整数据,比副本省空间多了
| 对比维度 | 副本池 | 纠删码池 |
|---|---|---|
| 存储利用率 | 低(3 副本 = 1/3) | 高(6+3 = 2/3) |
| CPU 开销 | 低 | 高(需要编码&解码运算) |
| I/O 延迟 | 低 | 较高(要读多个块才能拼回数据) |
| 典型场景 | RBD 块设备、高性能场景 | RGW 对象存储、冷数据归档 |
| 最多能坏几块盘 | size-1 块(3副本最多坏2块) | 任意 m 块(6+3 最多坏 3 块) 6是数据块(k), 3是校验块(m) |
📌 生产环境推荐用副本池,除非你对容量极度敏感且能接受性能损耗
PG 概述
什么是PG
Ceph 存数据的过程:对象 → Pool → PG → OSD
💡 OSD 是什么? OSD 本质上是一个进程 + 一块盘
说 osd.0 就是指
/dev/sda上的那个守护进程,说"数据写到 osd.3"就是写到 osd.3 背后的那块物理盘上后面讲的 peering、backfill、磁盘 I/O,都是在说 OSD 进程在操作它背后的那块盘
Object(对象) --CRUSH①--> Pool 下的某个 PG --CRUSH②--> OSD 集合
📌 CRUSH 在数据落地过程中用了两次:
- 第一次负责逻辑分组(对象归哪个 PG)
- 第二次负责数据落盘(PG 的副本落哪几块盘)
🧱 Pool 和 PG 的关系?
Pool 是 PG 的容器——一个 Pool 下挂着若干个 PG,PG 是 Pool 内部数据分布的最小单位
- 对象先命中某个 Pool,再由 CRUSH 哈希到该 Pool 下的某个 PG,最终落盘到 OSD
📌 PG 的数量远小于对象的数量——这才是 PG 存在的意义:
一个 PG 里可以存放成千上万个对象
PG.7(一个 PG)
├── obj1(4MB)
├── obj8(4MB)
├── obj15(4MB)
├── ...(成千上万个对象)
└── objN(4MB)
====================================
一个 Pool 里的数量对比:
对象:几百万个(甚至上亿) ← 海量
│ 'CRUSH 哈希收敛'
▼
PG:几百个(通常 32 ~ 1024) ← 少量
│ 'CRUSH 再计算'
▼
OSD:几十块盘 ← 更少
-
PG 做的就是聚合收敛——把海量对象哈希到少量 PG 中,规模从百万级降到千级
-
迁移时以 PG 为单位搬——一次搬"一筐对象",而不是一个一个搬
- 加减 OSD 时也只迁移受影响的 PG
PG 数量
📌 官方公式:
OSD 数量 × X
PG = ---------------
pool 的 size(副本数)
X = 每块 OSD 期望承载的 PG 数量,官方推荐 100 左右
🧱 这个公式到底在算什么?
核心逻辑:先定每块 OSD 背多少个 PG 合理,再反推池里该建多少个 PG
# PG 均匀散落在 OSD 上:
PG 总数 × size
每块 OSD 背的 PG 数 = ---------------
OSD 数量
# 反过来,已知每 OSD 期望背 X 个 PG,求 PG 总数:
OSD 数量 × X
PG 总数 = ---------------
size
PG 总数太多还是太少?
| PG 总数 | 后果 |
|---|---|
| 太少 | 数据分布不均,个别 OSD 成为"热点",忙的忙死闲的闲死 |
| 太多 | PG 元数据膨胀,peering(互相同步状态) / scrub (校验数据一致性)开销暴增,CPU 和内存吃紧 |
-
公式里塞 X=100 就是为了让 PG 总数落在适中区间
-
Ceph 的
mon_max_pg_per_osd默认上限是 250- 算是一种硬保护,防止 PG 总数失控
回到公式——代入算一下:
示例①:9 块 OSD,3 副本
9 × 100
PG = --------- = 300 → 取最近的 2 次方 → 256
3
'验证:256 × 3 / 9 = 每 OSD 约 85 个 PG'
示例②:200 块 OSD,3 副本
200 × 100
PG = ----------- ≈ 6666 → 取最近的 2 次方
3
2^12 = 4096 ← 差 2570
2^13 = 8192 ← 差 1526(更近)
∴ 集群 PG 总量取 2^13 = 8192 比较合理
'验证:8192 × 3 / 200 = 每 OSD 约 123 个 PG,仍在合理范围'
💡 结果取最近的 2 的幂(方便数据均匀分布)
算完后顺手验一下:
PG总数 × size ÷ OSD数是否在 100~250 之间
size VS min_size
这两个参数是副本池容错的核心
| 参数 | 含义 | 生产推荐值 |
|---|---|---|
size副本数 |
数据一共存几份(包含原始那份) | ≥ 3 |
min_size与最小副本数 |
I/O 服务需要的最少可用副本数 | size - 1(如 3 副本时设为 2) |
工作机制:
- 集群正常时,所有
size个 OSD 上的数据一致 - 坏一块盘,剩余副本 ≥
min_size→ I/O 照常跑 - 剩余副本 <
min_size→ 池暂停 I/O 或只读,优先保数据一致性,宁可停服也不丢数据
💡 这就是 Ceph 的"宁死不屈"机制——数据安全比服务可用性更重要
🌰实战:把 3 副本改成 5 副本,同时提高 min_size
1)查看PG状态
root@Ceph-201 ~# ceph pg stat
1 pgs: 1 active+clean; 449 KiB data, 284 MiB used, 5.3 TiB / 5.3 TiB avail
root@Ceph-201 ~# ceph pg dump
'所有 PG 详细状态'
version 1287
stamp 2026-05-26T03:38:21.766113+0000
last_pg_scan 0
................
2)查看默认池现有规则
root@Ceph-201 ~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2
'可以查看指定的参数' # get 池子 key
root@Ceph-201 ~# ceph osd pool get .mgr size
size: 3
root@Ceph-201 ~# ceph osd pool get .mgr min_size
min_size: 2
3)修改规则
root@Ceph-201 ~# ceph osd pool get .mgr pg_autoscale_mode
pg_autoscale_mode: on
'如果开着 autoscale_mode,系统可能在你手动改完 pg_num 后立刻又给调回去'
# 我们在后面存储池管理中详细介绍这个选项
root@Ceph-201 ~# ceph osd pool set .mgr size 5
set pool 1 size to 5
root@Ceph-201 ~# ceph osd pool set .mgr min_size 3
set pool 1 min_size to 3
root@Ceph-201 ~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 5 min_size 3 crush_rule 0
# 改成 5 副本后可以容忍任意 2 块盘故障(5-3=2),但代价是容量利用率更低
Peering 与 Backfill 详解
Peering —— PG 状态协商
🧱 前置概念:acting set 与 up set
在理解 peering 之前,先搞清楚 PG 里的 OSD 是怎么组织的
CRUSH 算法为每个 PG 算出一个 OSD 列表,指明该 PG 的副本应该落在哪几块盘上——这个列表就是 acting set
🌰 比如
PG.7的 acting set =[OSD.0, OSD.1, OSD.2],意思是这个 PG 的 3 个副本(size=3)应分别存放在 OSD.0、OSD.1、OSD.2 三块盘上
🧱 主 OSD(Primary)
acting set 中的第一个 OSD 被指定为 主 OSD(Primary),其余为副本 OSD
| 角色 | 谁 | 干什么 |
|---|---|---|
| 主 OSD | acting set 的第一个 | 接收客户端读写请求、将写操作同步到副本、驱动 peering / recovery / backfill |
| 副本 OSD | acting set 的其余位置 | 被动响应主 OSD 指令,同步数据、响应 log 查询 |
🌰
PG.7的 acting set =[OSD.0, OSD.1, OSD.2]→ OSD.0 是主,OSD.1 / OSD.2 是副本
正常情况下,还有一个 up set(当前实际在干活的 OSD 列表),两者保持一致:up set = acting set
如果某个 OSD 挂了,Monitor 会临时指派替代者,此时 up set 和 acting set 就不一致了(即后文的"临时 PG"机制)
| 概念 | 含义 | 一句话 |
|---|---|---|
acting set |
CRUSH 算出的目标 OSD 集合 | "应该在哪" |
up set |
当前实际在干活的 OSD 集合 | "实际在哪" |
🧱 Peering 是什么?
PG 的 acting set 里的 OSD 之间互相沟通、协商状态,达成共识——谁有最新数据、谁落后了、日志进度对齐到哪了
[!tip]
⚠️ 注意:PG 本身是逻辑实体,不干活
peering 的实际执行者是 acting set 里的 OSD 进程,由主 OSD 牵头、副本 OSD 响应——本质上就是这几个 OSD 在替这个 PG "对账"
📌 通俗理解:peering 就像三个副本"开会"
- "你到哪了?我写到 log 第 100 条了""我才到 95,等我补一下"
- 先把状态对齐,再决定下一步动作
什么时候会触发 peering?
| 触发场景 | 说明 |
|---|---|
| OSD 挂了又恢复 | 它上面的 PG 落后了,需要和同伴对账 |
| PG 数量变化 | pg_num / pgp_num 变了,PG 哈希边界重划,全部 PG 重新 peering |
| OSD 增删 | CRUSH 重新分配 PG 到不同 OSD |
| 集群重启 | 所有 PG 从零开始协商状态 |
Peering 的过程(简化版)
💡 一句话:说"PG.7 在 peering"和"主 OSD 在替 PG.7 peering"是同一件事
PG 是逻辑实体不干活,peering 由 acting set 里的 OSD 进程实际执行
PG.7 的 acting set = [OSD.0, OSD.1, OSD.2]
OSD.0 = 主 OSD(Primary)
其余 OSD 为副本 OSD,只被动响应主 OSD 的指令
═══════════════════════════════════════
Step 1: '主 OSD' 发起 peering 请求
┌─────────────────────────────────────┐
│ OSD.0 (Primary) │
│ │ │
│ │ PG.7 peering 报一下你们的 │
│ │ PG Log 最后一条序号 │
│ │ │
│ ├──────→ OSD.1 ──→ 回复: log #100 │
│ └──────→ OSD.2 ──→ 回复: log #98 │
└─────────────────────────────────────┘
Step 2: 确定权威日志(Authoritative Log)
┌─────────────────────────────────────┐
│ Primary 对比三份 log: │
│ OSD.0: #100 (自己就是最新的) │
│ OSD.1: #100 ✅ 一致 │
│ OSD.2: #98 ❌ 落后 2 条 │
│ │
│ 权威日志 = OSD.0 的 log │
│ 原则:挑最完整的一份 │
│ │
│ ⚠️ 前提:被选中的 log 必须连续、 │
│ 且属于当前 PG epoch——防止网络分区后 │
│ 旧主带着"过期最长 log"回来造成脑裂 │
└─────────────────────────────────────┘
Step 3: 状态判定——该走哪条恢复路径?
┌─────────────────────────────────────┐
│ OSD.2 只差 2 条 log │
│ → 走 recovery(增量恢复) │
│ → OSD.2 回放缺失的 log 条目即可 │
│ │
│ 如果 OSD.2 整个 PG 目录都丢了 │
│ → 走 backfill(全量回填) │
└─────────────────────────────────────┘
📌 peering 本身不搬数据,只是协商状态 + 决定恢复策略
数据搬运是 recovery 或 backfill 的事
🧱 PG Log vs 实际数据
peering 过程中反复提到的"PG Log"到底是什么?跟用户存的数据是一回事吗?
PG Log(操作日志) 实际数据(对象内容)
───────────────────────── ─────────────────────
记录"发生过什么修改操作"(写/删/改/克隆等) 用户存的东西本身
比如: 比如:
#98 write obj15 obj15 = 4MB(照片的第 3 个分片)
#99 delete obj8 obj1 = 4MB(文档的第 1 个分片)
#100 modify obj3 obj3 = 4MB(视频的第 5 个分片)
像一个"记账本" 像一个"仓库"
peering 对账本 → 轻量,秒级完成 scrubbing 翻仓库逐件盘点 → 重,费 I/O
📌 这就是为什么 peering 能几百个 PG 同时做(只对日志条目,几乎不碰磁盘)
而 backfill / recovery 要限流(搬实际数据),
scrubbing也要限速(逐字节读副本比对,同样是重 I/O)
为什么 peering 多了会"风暴"?
每个 PG peering 时,acting set 里的 OSD 要来回发消息
关键前提:一块 OSD 上托管着很多 PG(按官方推荐 ~100 个),每个 PG 的 acting set 都可能包含这块 OSD
1 个 PG peering:
只有这 1 个 PG 的 acting set 里那几块 OSD 在通信 → 轻量,秒级完成
100 个 PG 同时 peering:
每块 OSD 上托管着 ~100 个 PG,这 100 个 PG 的 peering 砸过来,
一块 OSD 可能同时卷入几十个 PG 的协商:
→ OSD 进程的消息队列堆成山
→ Monitor 心跳超时
→ PG 被标记为 down / stale(误伤!)
这就是前面说的 peering 风暴——不是 peering 本身开销大,而是几百个 PG 同时 peering 时,OSD 的消息处理能力被打穿
Backfill —— 全量数据回填
🧱 Backfill 是什么?
当某个 OSD 上整个 PG 的数据需要从头同步时,Ceph 不走逐条 log 回放(recovery),而是直接扫描并全量拷贝 PG 的所有对象——这就是 backfill
recovery = 差几条 log,逐条追
backfill = 整个 PG 都要搬,全量拷
什么时候走 backfill 而不是 recovery?
| 场景 | 走哪条路 | 原因 |
|---|---|---|
| OSD 短暂挂了又回来,只差几条 log | recovery | 增量补就行 |
| 新 OSD 加入集群,上面啥数据都没有 | backfill | 全量搬 |
| PG 扩容,PG 被分配到之前未托管过它的 OSD | backfill | 该 OSD 上没有这个 PG 的存量数据,只能全量搬 |
| OSD 永久替换(盘坏了换了块新的) | backfill | 从零开始 |
Backfill 的过程
和 peering 一样,backfill 也是由主 OSD 驱动的——主 OSD 扫描 该PG 落在自己盘上的所有对象,全量推送给目标 OSD
场景:OSD.3 是新加入的盘,PG.7 被 CRUSH 分配到了它上面
PG.7 acting set = [0, 1, 2] → OSD.3 加入后 → [0, 1, 3]
┌──────────────────────────────────────────────┐
│ 主 OSD (OSD.0) │
│ PG.7 目录: │
│ ├── obj1 (4MB) │
│ ├── obj8 (4MB) │
│ ├── obj15 (4MB) │
│ └── ... (共 10000 个对象,约 40GB) │
└──────────┬───────────────────────────────────┘
│
│ Backfill:全量顺序扫描 & 推送
│
▼
┌──────────────────────────────────────────────┐
│ OSD.3 (新盘,PG 目录为空) │
│ │
│ backfill 进度: │
│ ████████████░░░░░░░░ 67% (6.7K / 10K obj) │
│ │
│ 磁盘写 I/O 持续拉满 │
└──────────────────────────────────────────────┘
同时,OSD.2 上的旧副本被标记为"待清理"(PG 成员变了)
为什么 backfill 不能太多并发?
先理解一个前提:backfill 的每一步——从源 OSD 读对象、写到目标 OSD——本质上都是磁盘顺序 I/O
- 这里的磁盘,就是指 OSD 背后的那块物理盘
🌰 单个 PG backfill 时(比如 PG.7):
源 OSD 上 PG.7 的对象在磁盘上是连续存放的
→ 磁头从 A 位置一路扫到 B 位置,一口气读完
→ 这是"顺序读"——磁头几乎不用跳,速度极快
一块盘上托管着几十上百个 PG,它们的对象各自占据不同的物理区域
当多个 PG 同时 backfill 时:
❌ 50 个 PG 同时 backfill 在同一块盘上:
磁盘被要求同时服务 PG.1、PG.7、PG.3... 的数据
原本每个 PG 都是"一口气读完"的顺序 I/O,
现在被搅在一起,磁头在不同 PG 的区域之间反复横跳
→ 顺序 I/O 退化成随机 I/O
→ 大量时间浪费在"寻道"上,实际读数据的时间占比暴跌
→ 吞吐量断崖式下跌,业务读写也被挤占
📌 核心:一块盘同一时间只做一件事(读或写某个 PG 的数据)效率最高,让它同时干好几件,磁头来回跳,总产出反而骤降
Peering → Recovery → Backfill 关系图
OSD 挂掉 / PG 变化 / 集群事件
│
▼
┌─────────┐
│ Peering │ ← 先协商,搞清楚"谁有、谁缺、缺多少"
└────┬────┘
│
▼
PG Log 差得少?──── 是 ──→ Recovery(增量回放 log)
│ │
否 ▼
│ 恢复完成 → active+clean
▼
Backfill(全量扫描 & 拷贝对象)
│ '扫描 = 主 OSD 读自己的盘'
│ '拷贝 = 写到目标 OSD 的盘'
▼
恢复完成 → active+clean
📌 一句话:peering 是"对账",recovery 是"打补丁",backfill 是"重装系统"。
PGP 是什么
PGP = Placement Group for Placement,即"用于数据放置的 PG 数量"
🧱 pg_num 和 pgp_num 的区别:
| 参数 | 干什么的 | 通俗理解 |
|---|---|---|
pg_num |
池里创建多少个 PG | 池里有多少个"调度组" |
pgp_num |
多少个 PG 参与数据分布 | 有多少个调度组实际在干活 |
📌
pgp_num ≤ pg_num,通常两者保持相等
🧱 为什么需要 pgp_num?——安全扩容的"调速阀门"
- 如果把 pg_num 和 pgp_num 同时拉满,集群瞬间要对所有已有数据重新分布
- 全部 PG 同时 peering,新PG 集中 backfill,I/O 直接被打穿
pgp_num 就是调速阀门:pg_num 决定有多少个 PG 存在,pgp_num 决定其中多少个真正在干活
安全扩容三步走:
1) 扩大 pg_num → 只创建新 PG 的数据结构,不实际迁移数据
2) 逐步调大 pgp_num → 每次只搬迁一部分 PG,集群平稳过渡
3) pgp_num 对齐 pg_num → 全部 PG 正常参与数据分布
📌 pgp_num 分步的本质是"限流"——让 PG 分批 peering + backfill,而非全部 PG 同时搅动
最终搬的数据总量差不多,但每批只扰动一部分 PG,集群始终保持可服务状态
🧱 为什么分步调能奏效?——回头看 peering 和 backfill
| 维度 | peering 风暴 | backfill 并发 |
|---|---|---|
| 瓶颈在哪 | OSD 消息队列 / CPU | 磁盘 I/O 带宽 |
| 什么感觉 | PG 假死(被误标 down/stale) | 业务 I/O 卡顿、延迟飙升 |
| 怎么控 | pgp_num 分步,减少同时 peering 的 PG 数 | pgp_num 分步 + osd_max_backfills 限速 |
💡 Ceph 默认
osd_max_backfills = 1(一次只回填 1 个 PG),就是怕 backfill 把磁盘打穿
⚠️ 生产环境:pg_num 和 pgp_num 最终必须等齐,否则新 PG 不参与数据放置
但不要一次同步拉满——先调 pg_num,再逐步放大 pgp_num,每步确认集群 active+clean 后再继续
root@Ceph-201 ~# ceph osd pool get .mgr pg_num
pg_num: 1
root@Ceph-201 ~# ceph osd pool get .mgr pgp_num
pgp_num: 1
'两者通常保持相等'
✅️ 使用 set 进行调整
临时PG
主 OSD 挂了怎么办❓️
CRUSH 会重新算 acting set,但 新主OSD 上还没数据——此时需要一个过渡机制,这就是临时 PG
| 概念 | 谁定的 | 什么时候变 | 一句话 |
|---|---|---|---|
acting set |
CRUSH 计算 | PG 数变化、OSD 增删 | "应该在哪" |
up set |
Monitor 根据 OSD 存活状态实时调整 | OSD 挂掉/恢复 | "实际在哪" |
📌 正常情况
acting set = up set当主 OSD 挂了,acting set 里换了新人但新人还没数据,up set 就让有数据的老人先顶班
acting set 和 up set 暂时不一致,这就是临时 PG
正常状态:
PG.7 的 acting set = [0, 1, 2]
up set = [0, 1, 2] ← 与 acting set 一致
OSD.0 = 主 OSD
────────────────────────────────────────
Step 1:OSD.0 故障
────────────────────────────────────────
CRUSH 重新计算 → acting set = [3, 1, 2]
OSD.3 被推举为新主 OSD,但盘上空空,还不能接读请求
────────────────────────────────────────
Step 2:申请临时 PG
────────────────────────────────────────
PG 向 Monitor 申请过渡方案
OSD.1(原副本,有最新数据)升任"临时主 OSD"
→ up set = [1, 3, 2] ← '临时干活阵容'
→ acting set = [3, 1, 2] ← CRUSH 的目标阵容(不变)
⚠️ acting set ≠ up set(过渡期不一致)
────────────────────────────────────────
Step 3:backfill 回填数据
────────────────────────────────────────
临时主 OSD.1 将 PG.7 数据全量推给 OSD.3
────────────────────────────────────────
Step 4:恢复正常
────────────────────────────────────────
OSD.3 数据同步完毕 → 临时 PG 取消
up set 恢复 = acting set = [3, 1, 2]
OSD.3 正式就任新主 OSD
PG 状态
PG 状态是判断集群数据分布是否健康的关键指标
日常只需重点关注 active + clean,其余都是过渡状态。
| 状态 | 含义 | 归类 |
|---|---|---|
active |
能正常处理读写 | ✅ 理想 |
clean |
所有副本齐全且内容一致 --> 没有缺失和待修复的副本 |
✅ 理想 |
[!tip]
上面两个同时出现(
active+clean)= 一切正常
| 状态 | 含义 | 归类 |
|---|---|---|
peering |
OSD 之间对 PG Log,协商谁最新谁落后 → 决定恢复策略 --> 对的是操作日志,不是数据本身 |
对账 |
recovering |
逐条回放 PG Log,差多少补多少 → "打补丁" | 增量恢复 |
backfill |
全量扫描该 PG 对象,从头拷贝到新 OSD → "重装系统" | 全量恢复 |
wait-backfill |
排队等 backfill(受 osd_max_backfills 限制)--> 默认一次只回填 1 个 PG |
限流 |
backfill-toofull |
目标 OSD 使用率超阈值,backfill 挂起 | ⚠️ 阻塞 |
peering → 决定走 recovering 还是 backfill → ✅️ 完成 →
active+clean
| 状态 | 含义 | 归类 |
|---|---|---|
remapped |
acting set ❌️≠❌️ up set,PG 正由临时阵容代管 → 临时 PG |
🔄过渡 |
creating |
PG 正在创建 | 一次性 |
splitting |
PG 数量扩容,正在分裂 | 一次性 |
replay |
OSD 崩溃后,PG 在等待客户端重放未确认操作 | 🔄过渡 |
| 状态 | 含义 | 归类 |
|---|---|---|
scrubbing |
逐字节比对副本的实际数据,发现静默损坏(bit rot) --> peering 是对 PG Log,scrub 是对数据本身 |
后台巡检 |
repair |
scrubbing 发现不一致 → 用正确副本覆盖损坏副本 | 后台修复 |
异常 / 降级状态:
| 状态 | 含义 |
|---|---|
degraded |
部分副本挂掉或落后,但剩余副本 ≥ min_size,还能接 I/O |
undersized |
当前可用副本数少于 size,但 ≥ min_size |
down |
该 PG 必要的数据副本全部不可达,PG 下线 |
incomplete |
PG 缺少关键信息(如日志断层),无法判断数据是否安全 |
inconsistent |
scrubbing 检测到副本间实际数据不一致 → 触发 repair |
stale |
PG 所在 OSD 长时间没向 Monitor 报心跳,Monitor 不知道它什么状态 |
inactive |
PG 不能处理读写,等待持有最新数据的 OSD 回来 |
unclean |
有对象副本数不达标(与 clean 相反),通常正在恢复中 |
peered |
peering 已完成(状态协商好了),但副本还没补够,暂不接客 |
[!IMPORTANT]
遇到 PG 异常的常规思路:
- 重启相关 OSD 服务
- 调整属性参数
- 重置 PG
存储池管理
1)创建副本存储池(默认类型)
root@Ceph-201 ~# ceph osd pool create xixi replicated
pool 'xixi' created
⚠️ '默认不指定池子类型 --> 就是副本池' --> replicated
2)创建纠删码存储池
root@Ceph-201 ~# ceph osd pool create haha erasure
pool 'haha' created
3)查看存储池列表
root@Ceph-201 ~# ceph osd pool ls
.mgr
xixi <-- ✅️ 副本池
haha <-- ✅️ 纠删池
👆 '这两个是我们刚创建的'
# 我们再加一个选项 detail
root@Ceph-201 ~# ceph osd pool ls detail
'查看存储池详细信息🔍'
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 📌 'crush规则0'
pool 2 'xixi' replicated size 3 min_size 2 crush_rule 0 📌 'crush规则0'
pool 3 'haha' erasure profile default size 4 min_size 3 crush_rule 1 📌 '规则1'
==========================================================
root@Ceph-201 ~# ceph osd crush rule ls
"有哪些规则" --> 📌 只列出名字
replicated_rule
erasure-code
'很明显一个是副本池默认的crush规则, 另一个是纠删码池的默认crush规则'
# 创建crush规则参考之前的笔记📚
🌰 副本规则 `create-replicated`
🌰 纠删码规则 `create-erasure`
✅️ ceph osd crush rule dump <规则名>
"这条规则内部长什么样" --> 📌 完整 JSON
# 查看故障域详细的规则规则
✅️ ceph osd pool set <存储池名称> <参数名> <参数值>
# 关联存储池到新规则
4)查看创建池子的pg和pgp数
✅️ '查看单个池的指定属性'
'默认相同' --> 32 = 2的5次方
# Ceph 会根据集群 OSD 数量和池的用量,自动计算并动态调整 PG 数量
📌 我们创建池子的时候,并没有指定pg数 ❌️ --> 生产环境一定要指定
root@Ceph-201 ~# ceph osd pool get xixi pg_num
pg_num: 32
root@Ceph-201 ~# ceph osd pool get xixi pgp_num
pgp_num: 32
root@Ceph-201 ~# ceph osd pool get haha pg_num
pg_num: 32
root@Ceph-201 ~# ceph osd pool get haha pgp_num
pgp_num: 32
| 命令 | 查看维度 | 一句话 |
|---|---|---|
rados df |
池 | "每个池用了多少、剩多少,按池算账" |
ceph osd df |
OSD 设备 | "每块盘用了多少、剩多少,按盘摸底" |
5)查看存储池利用率
root@Ceph-201 ~# rados df
POOL_NAME USED OBJECTS CLONES COPIES ....
.mgr 1.3 MiB 2 0 6 ....
haha 0 B 0 0 0 ....
kpyun 0 B 0 0 0 ....
xixi 0 B 0 0 0 ....
'📌 重点在下面的统计'
total_objects 2
total_used 285 MiB
total_avail 5.3 TiB
total_space 5.3 TiB
root@Ceph-201 ~# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE AVAIL %USE PGS STATUS
0 hdd 0.293 1.000 300 GiB 300 GiB 0.01 44 up
1 hdd 0.488 1.000 500 GiB 500 GiB 0.01 58 up
...........
6)重命名存储池
root@Ceph-201 ~# ceph osd pool rename haha hehe
pool 'haha' renamed to 'hehe'
root@Ceph-201 ~# ceph osd pool ls | grep hehe | wc -l
1
7)创建时指定 PG 数量和关闭自动伸缩
root@Ceph-201 ~# ceph osd pool get .mgr pg_autoscale_mode
pg_autoscale_mode: on
'系统池这个选项是开着的 --> 系统可能在你手动改完 pg_num 后立刻又给调回去'
root@Ceph-201 ~# ceph osd pool create kpyun 128 128 --autoscale_mode off
✅️ 128 128 = pg_num 128, pgp_num 128
📌 自动伸缩(pg_autoscale_mode)是什么?
Ceph 会根据集群 OSD 数量和池的用量,自动计算并动态调整 PG 数量
如果开着 autoscale,系统可能在你手动改完 pg_num 后立刻又给调回去
为什么创建时关掉它? 既然你手动指定了 128 个 PG,就说明你算好了PG数量了
--autoscale_mode off告诉 Ceph "PG 数量我来定,你别插手"同理,后续用
set修改 pg_num 前也需要先关 autoscale
'我在创建这个池子的时候,默认不指定池的类型 --> 副本池'
root@Ceph-201 ~# ceph osd pool ls detail | grep kpyun
pool 4 'kpyun' replicated size 3 min_size 2 crush_rule 0
root@Ceph-201 ~# ceph osd pool get kpyun pg_num
pg_num: 128
root@Ceph-201 ~# ceph osd pool get kpyun pgp_num
pgp_num: 128
'这次都是128 --> 而不是32'
📌 Ceph 的逻辑:⚠️ 创建一个池之后务必声明它的用途
否则 Monitor 不知道这个池是存 RBD 镜像还是当 CephFS 元数据池,持续报
HEALTH_WARN❌️
| 类型 | 业务 | 一句话 |
|---|---|---|
rbd |
块存储 | "这池子给虚拟机/云盘用的" |
cephfs |
文件系统 | "这池子给共享文件存储用的" |
rgw |
对象存储 | "这池子给 S3 / Swift 对象网关用的" |
root@Ceph-201 ~# ceph -s | grep -A2 health
health: HEALTH_WARN ❌️
Degraded data redundancy: 6 pgs undersized
3 pool(s) do not have an application enabled
📌 集群里有 3 个池子还没声明"我是干啥用的"
1)声明用途
✅️ ceph osd pool application enable <池名> <类型>
root@Ceph-201 ~# ceph osd pool application enable kpyun rbd
2)查看已声明的用途
✅️ ceph osd pool application get <池名>
root@Ceph-201 ~# ceph osd pool application get kpyun
{
"rbd": {}
}
删除存储池的两道锁
Ceph 为了保护数据不被人手滑删掉,设计了两道锁:
机制一:nodelete 标记(池级锁)
给'某个存储池'打上 nodelete=true → 该池不可删除 ❌️
'默认值':false(可删除)✅️
机制二:mon_allow_pool_delete 全局开关(集群级锁)
Monitor 级别的总闸,📌'控制整个集群是否允许删池'
'默认值':false(不允许删除)❌️
⚠️ 两道锁都有一票否决权 --> 任一不通过都不能删池
| 锁 | 允许删除的条件 | 默认值 | 默认能删吗 |
|---|---|---|---|
nodelete(池级) |
false |
false |
✅ 能 |
mon_allow_pool_delete(集群级) |
true |
false |
❌ 不能 |
📌 实际删池时,
nodelete默认就是false(没上锁),真正卡住你的是全局开关mon_allow_pool_delete
- 所以实验里只需要翻这一道开关就够了
- 不是只开了一个就能删,而是另一个本来就没关
- 📌 生产环境建议:
nodelete=true+mon_allow_pool_delete=false- 双重保险,防止手滑
ceph config 方式删除(推荐)
'删除池的完整流程 —— ceph config 版'
1)强制删除试试
# 由于这是一个高风险操作,Ceph要求您提供更强的确认
1.需要输入两次存储池名称(xixi xixi)
2.使用 --yes-i-really-really-mean-it 参数
# 两次really强确认
root@Ceph-201 ~# ceph osd pool rm xixi xixi --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; --> '删除失败' ❌️
"在删除存储池之前,您必须先将mon_allow_pool_delete配置选项设置为true"
2)检查 nodelete 标记
root@Ceph-201 ~# ceph osd pool get xixi nodelete
nodelete: false
'池级锁默认false --> 可以删除'
3)在 monitor 和 global 级别都开启允许删除
'global = 所有守护进程(mon/osd/mgr/mds/client),mon = 仅 Monitor'
# 实际上:设了 global,就完全不需要再设 mon
✅️ 老运维只认 mon, 后来 global 出现了,有些人就"两条都写上,求个心安"
root@Ceph-201 ~# ceph config set mon mon_allow_pool_delete true
root@Ceph-201 ~# ceph config set global mon_allow_pool_delete true
4)确认开关已生效
root@Ceph-201 ~# ceph config get mon mon_allow_pool_delete
true
root@Ceph-201 ~# ceph config get global mon_allow_pool_delete
Error EINVAL: unrecognized entity 'global'
'这是为什么??'
# global 不能用 get 查(不是具体守护进程类型),用 dump 来看
root@Ceph-201 ~# ceph config dump | grep mon_allow_pool_delete
ceph config dump # 导出所有配置项
global mon_allow_pool_delete true
mon mon_allow_pool_delete true
'global 和 mon 都 true,确认生效'
5)执行删除
root@Ceph-201 ~# ceph osd pool rm xixi xixi --yes-i-really-really-mean-it
pool 'xixi' removed
root@Ceph-201 ~# ceph osd pool ls | grep xixi | wc -l
0
6)安全收尾——关掉开关
root@Ceph-201 ~# ceph config set mon mon_allow_pool_delete false
root@Ceph-201 ~# ceph config set global mon_allow_pool_delete false
ceph config 配置管理
Ceph 从 Squid 版本开始,引入了集中化配置数据库(Configuration Database),ceph config 命令是统一入口
传统 ceph.conf vs 配置数据库
传统方式:'分散管理,一致性难保证'
1.N 个节点各存一份 `ceph.conf`
2.改配置 = 挨个 SSH 改文件,漏一台就不一致
---------------------------------------------
现代方式(Config DB):📌'Monitor 集中存储'
1.Monitor 内存着一份"配置总账"(存在 RocksDB 里)
2.你敲一条 `ceph config set` 写入总账,所有节点的守护进程自动拉取
3.一份数据,全集群读
💡 RocksDB 又是什么?
它是 Facebook 开源的一款嵌入式键值(Key-Value)数据库
非常轻量 --> 不需要单独部署服务,直接嵌在 Monitor 进程里跑,负责把配置数据持久化到磁盘上
Monitor 用它存两类东西:
① 配置数据库(Config DB)
② 集群 Map(OSD Map / PG Map / CRUSH Map 等)
说白了就是 Ceph 自己的"小账本"
优先级(由高到低):
① Config DB(
ceph config set)→ ②ceph.conf文件 → ③ 代码内置默认值
📌 最佳实践:日常运维优先用 ceph config 在线改,ceph.conf 仅作为静态补充或离线批量配置
常用命令
| 命令 | 说明 |
|---|---|
ceph config dump |
导出所有配置项 常配合grep过滤 |
ceph config get <target> <option> |
查配置——<target> 可以是类型级或实例级 |
ceph config set <target> <option> <val> |
设配置——<target>可以是类型级或实例级 |
ceph config rm <target> <option> |
删除配置(同上) |
ceph config show <target> <option> |
查看某个进程实际生效的配置 合并全部来源,给出最终生效值 |
ceph config assimilate-conf -i ceph.conf |
把老 ceph.conf 导入配置数据库 |
| 粒度 | 例子 |
|---|---|
| 类型级 --> 影响一类守护进程 | mon / osd / mgr |
| 实例级 --> 精确到一个具体进程 | osd.0 / mon.Ceph-201 |
[!tip]
💡
get/set/rm的<target>可以是类型级(mon)也可以是实例级(mon.Ceph-201)
show通常跟实例级,看某个具体进程实际跑的是什么配置
💡 守护进程命名规则:`type.id`
osd.0 → type.id
│ └── OSD 编号(Ceph 内部'守护进程编号',不是 Linux PID(重启会变))
└── 守护进程类型(mon / osd / mgr / mds / client)
`osd.0` = `osd` 类型的 `0` 号实例
📌 Monitor 用主机名当 ID(`mon.Ceph-201`),MDS 和 Manager 同理
[!IMPORTANT]
📌
global是虚拟赋值层
可以往里写(
set),但往里读(get)就报unrecognized entity❌️验证
global是否生效用ceph config dump | grep
| 取值 | 层级 | 影响范围 | set |
get |
|---|---|---|---|---|
global |
全局 | 所有守护进程 | ✅ | ❌,用 dump 查 |
mon |
类型 | 所有 Monitor | ✅ | ✅ |
osd |
类型 | 所有 OSD | ✅ | ✅ |
mgr |
类型 | 所有 Manager | ✅ | ✅ |
mds |
类型 | 所有 MDS | ✅ | ✅ |
client |
类型 | 所有客户端 | ✅ | ✅ |
osd.0 |
实例 | 仅 osd.0 这一个进程 | ✅ | ✅ |
mon.Ceph-201 |
实例 | 仅 Ceph-201 上的 Monitor | ✅ | ✅ |
'实操示例'
1)查看 monitor 级别是否允许删池
root@Ceph-201 ~# ceph config get mon mon_allow_pool_delete
false
2)设置 monitor 级别配置
root@Ceph-201 ~# ceph config set mon mon_allow_pool_delete true
3)查看mon.Ceph-201的所有配置
'这里已经具体到某台主机了'
root@Ceph-201 ~# ceph config show mon.Ceph-201
NAME ALUE
debug_mon 20/20
keyring $mon_data/keyring
log_to_file false
public_network 10.0.0.0/24
................
✅️ '后面也可以跟某个具体配置'
root@Ceph-201 ~# ceph config show mon.Ceph-201 public_network
10.0.0.0/24
4)global全局配置
root@Ceph-201 ~# ceph config get gobal public_network
Error EINVAL: unrecognized entity 'gobal' ❌️
'需要配置 👇'
root@Ceph-201 ~# ceph config dump | grep public_network
global advanced public_network 10.0.0.0/24
Dashboard 速览
Dashboard 是 Ceph 自带的 Web 图形化管理界面(端口 8443),不想敲命令的时候用它
Tentacle(v20)换了新 UI —— 首页改叫 Overview,界面更现代
🔹 Tentacle 新版主要功能:
| 功能 | 一句话 |
|---|---|
| 多集群管理 | 一个页面管好几个 Ceph 集群,不用来回切 统一看健康状态、容量、告警 |
| NVMe 高速存储 | 网页上配 NVMe 盘、分命名空间 |
| 对象存储(RGW) | 多活同步、冷热分层、过期删除、权限策略,全在页面上点 |
| 文件共享(SMB) | Linux 上的 CephFS 当作 Windows 共享文件夹用 |
| 性能监控 | 看磁盘读写速度、延迟、带宽趋势 |
| 统一登录(OAuth2) | 对接公司已有的账号系统,不用单独记密码 |
| 配置管理 | 改副本数、改 PG 数、换 CRUSH 规则,不用敲命令 |
| 角色权限(RBAC) | 管理员、只读、块存储管理员、对象存储管理员...各看各的 |
[!tip]
📌 Tentacle 附带的监控组件:Prometheus 3.6 + Grafana 12 + Alertmanager 0.28
💡 生产环境别忘了把 Dashboard 的自签名证书换成正规 CA 签发的证书
内置角色:
| 角色 | 能干啥 | 一句话 |
|---|---|---|
administrator |
全部权限 | "超级管理员,什么都能动" |
read-only |
只能看 | "参观者,点不坏任何东西" |
block-manager |
RBD 块设备 | "管虚拟机云盘的" |
rgw-manager |
对象网关 | "管 S3 存储桶的" |
cephfs-manager |
文件系统 | "管共享目录的" |
| ceph dashboard 命令 | 干什么 |
|---|---|
ac-user-create <用户名> -i <密码文件> <角色> |
创建用户 |
ac-user-show <用户名> |
查看用户信息 |
ac-user-set-password <用户名> -i <密码文件> |
修改密码 |
ac-user-set-roles <用户名> <角色> |
修改角色 |
ac-user-delete <用户名> |
删除用户 |
📌 复杂的操作上 Web 界面点,命令行记住👆上面 5 条够用了
'实例'
1)创建管理员用户 jiu,密码从文件读入
root@Ceph-201 ~# echo 'Redhat123.com' > /root/passwd.txt
⚠️ 防止 Password is too weak❌️ --> ✅️ '密码设置复杂一点'
root@Ceph-201 ~# ceph dashboard ac-user-create jiu -i /root/passwd.txt administrator
✅️ 刚创建的同时,把用户信息也打印出来了
{"username": "jiu", "password": "$2b$12$xn ...xxx", "roles": ["administrator"]
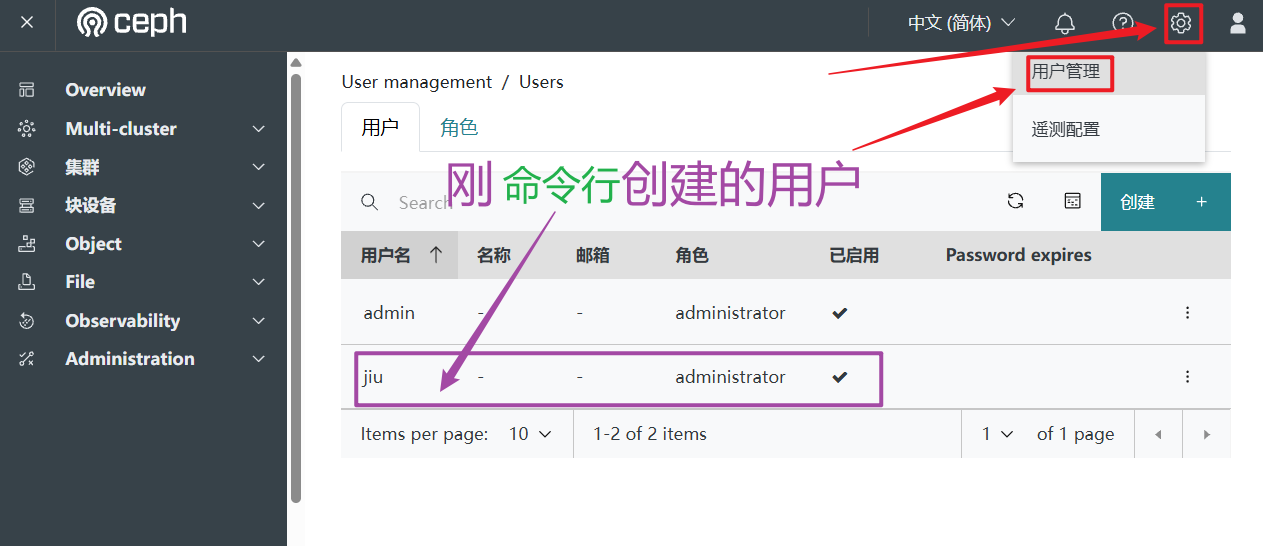
2)查看 admin 用户信息
root@Ceph-201 ~# ceph dashboard ac-user-show admin
✅️ 是admin用户呀!
{"username": "admin", "password": "$2b$12$Vq..xxx"
3)修改 jiu 的密码
root@Ceph-201 ~# echo 'Oldboy123.com' > /root/passwd.txt
root@Ceph-201 ~# ceph dashboard ac-user-set-password jiu -i /root/passwd.txt
✅️ 选项 --> ac-user-set-password
✅️ 后面没有角色, 只有一个密码文件📃
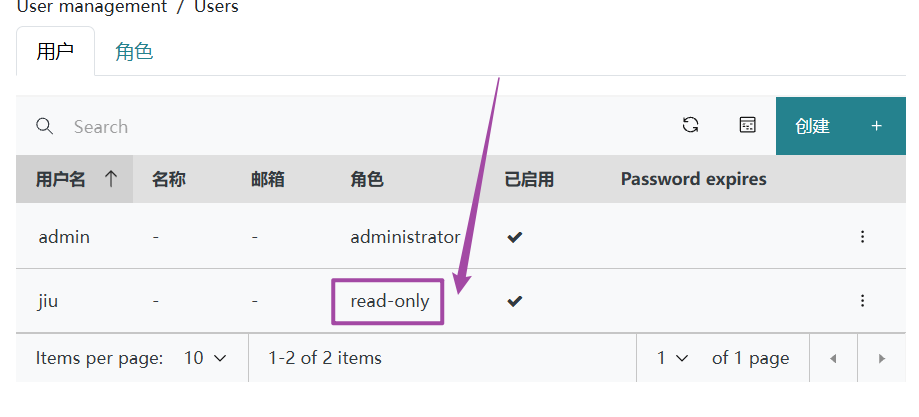
4)把 jiu 降级为只读
root@Ceph-201 ~# ceph dashboard ac-user-set-roles jiu read-only
✅️ 选项 & 更换的角色
{"username": "jiu", ...xxx "roles": ["read-only"],
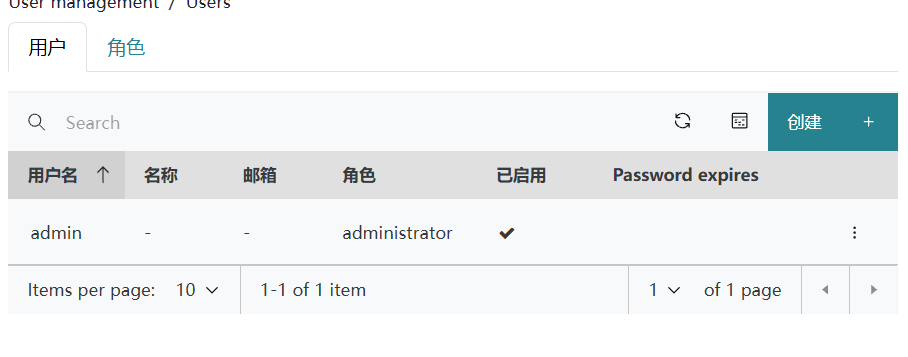
5)删除 jiu
root@Ceph-201 ~# ceph dashboard ac-user-delete jiu
User 'jiu' deleted
Manager 的 Active / Standby 机制
Dashboard 本质上是 Manager 进程提供的 HTTP 服务
URL: https://Ceph-201:8443/
root@Ceph-201 ~# curl -k https://Ceph-201:8443/
# -k 跳过证书
This resource can be found at <a href="https://10.0.0.202:8443/">
✅️ -L 可以实现自动跳转
🔹 为什么访问 Ceph-201 却跳到 Ceph-202❓️
1)显示集群中 active / standby
root@Ceph-201 ~# ceph -s | grep mgr
mgr: Ceph-202.xdeumk(active, since 88m), standbys: Ceph-201.cxdvrq
'Ceph 集群通常有多台 Manager(冗余),但同一时刻只有一个是 active'
✅️ 此时 active --> Ceph-202
✅️ 谁当 active mgr,Dashboard 就跑在谁上面
2)试试Ceph-202
root@Ceph-201 ~# curl -kI https://Ceph-202:8443/
HTTP/1.1 200 OK
'这个是可以通的'
https://Ceph-201:8443/
│
└→ standby mgr(Ceph-201): "我不当家,去Ceph-202找active"
│
└→ 重定向 → https://10.0.0.202:8443/
✅️ 访问 standby mgr 的 Dashboard 端口,会被重定向到 active mgr
🔹 选举规则
Manager 选举是先到先得——两边的 mgr 容器同时启动,谁先向 Monitor 注册成功谁就是 active,晚了半拍就成 standby
- 这不是故障,是正常的 HA 设计:active 挂了,standby 秒级接替
3)查看mgr的状态
root@Ceph-201 ~# ceph mgr stat
✅️ JSON 格式更详细
{
"epoch": 72,
"available": true,
"active_name": "Ceph-202.xdeumk",
"num_standby": 1
}
4)看 Dashboard 实际跑在哪个 IP
root@Ceph-201 ~# ceph mgr services
✅️ 这个命令是真的实用
{
"dashboard": "https://10.0.0.202:8443/"
}
5)手动踢掉 active mgr,触发 standby 接替
✅️ 被踢的原 active 重启
# 用于主动切换(维护前可能会用)
root@Ceph-201 ~# ceph mgr fail
root@Ceph-201 ~# ceph mgr services
{
"dashboard": "https://10.0.0.201:8443/"
}
root@Ceph-201 ~# curl -kI https://Ceph-201:8443/
HTTP/1.1 200 OK ✅️
🔹 把 Dashboard 固定在某台机器上
如果不想让它跟着 active mgr 跑,可以显式指定 IP:
root@Ceph-201 ~# ceph config set mgr mgr/dashboard/server_addr 10.0.0.201
root@Ceph-201 ~# ceph config get mgr mgr/dashboard/server_addr
10.0.0.201
'终于用上 rm 选项了'
root@Ceph-201 ~# ceph config rm mgr mgr/dashboard/server_addr
root@Ceph-201 ~# ceph mgr fail
✅️ ceph mgr fail 一踢,mgr 重启 --> 重新加载配置,内存里的旧值清了
# mgr 不会热加载,得重启才生效
常用操作速查
# ===================================
# 集群状态
# ===================================
ceph -s # 集群整体健康状态
ceph -w # 实时监控集群变化
ceph osd tree # OSD 树(含 class / 权重 / 状态)
ceph osd df # OSD 磁盘使用率
rados df # 存储池使用率(按池算账)
ceph mgr stat # Manager active/standby 状态(JSON)
ceph mgr services # Dashboard 实际跑在哪个 IP
# ===================================
# 存储池管理
# ===================================
ceph osd pool ls # 列出所有存储池
ceph osd pool ls detail # 存储池详细信息(类型/副本数/规则)
ceph osd pool create <name> <pg> <pgp> replicated # 创建副本池
ceph osd pool create <name> <pg> <pgp> erasure # 创建纠删码池
ceph osd pool create <name> <pg> <pgp> --autoscale_mode off # 创建时关闭自动伸缩
ceph osd pool rename <old> <new> # 重命名存储池
ceph osd pool rm <name> <name> --yes-i-really-really-mean-it # 删除存储池(双重确认)
ceph osd pool application enable <name> <rbd|cephfs|rgw> # 声明池用途
# ===================================
# 池属性管理
# ===================================
ceph osd pool get <name> <param> # 查单个属性(size / min_size / pg_num ...)
ceph osd pool set <name> <param> <val> # 修改属性
ceph osd pool get <name> pg_autoscale_mode # 查看自动伸缩是否开启
ceph osd pool get <name> nodelete # 查看池级删除锁状态
# ===================================
# CRUSH 规则
# ===================================
ceph osd crush rule ls # 列出所有 CRUSH 规则(只列名字)
ceph osd crush rule dump <rule> # 查看规则完整 JSON(故障域/副本数/设备类型)
# ===================================
# PG 管理
# ===================================
ceph pg stat # PG 状态概览
ceph pg dump # 所有 PG 详细状态(常配合 grep)
# ===================================
# 配置管理 (ceph config)
# ===================================
ceph config dump # 导出所有配置项(常配合 grep 过滤)
ceph config dump | grep <keyword> # 按关键字查配置
ceph config get <target> <option> # 查配置(类型级/实例级)
ceph config set <target> <option> <val> # 设配置(global/mon/osd/mgr 等)
ceph config rm <target> <option> # 删除配置
ceph config show <target> # 查看进程实际生效的全部配置
# ===================================
# Dashboard 用户管理
# ===================================
ceph dashboard ac-user-create <user> -i <passwd_file> <role> # 创建用户
ceph dashboard ac-user-show <user> # 查看用户信息
ceph dashboard ac-user-set-password <user> -i <passwd_file> # 修改密码
ceph dashboard ac-user-set-roles <user> <role> # 修改角色
ceph dashboard ac-user-delete <user> # 删除用户