Ceph 集群开篇

- Ceph Documentation
- 官方文档📄
一、Ceph 概述
Ceph 是什么
Ceph 是一个开源的分布式存储系统,它把每一块待管理的数据切分为固定大小的对象(object),并以对象为原子单元完成数据存取
底层存储服务由多个主机(host)组成的存储集群提供,该集群被称为 RADOS(Reliable Automatic Distributed Object Store)——可靠、自动化、分布式、对象存储系统
RADOS 通俗理解:把四个字母拆开就是它的全部秘密:
| 字母 | 含义 | 通俗解释 |
|---|---|---|
| Reliable | 可靠 | 每份数据自动存 3 份,坏一台机器不丢数据 |
| Automatic | 自动化 | 你不用管数据放哪块盘,系统自己决定 |
| Distributed | 分布式 | 多台机器绑在一起干活,不是单机 |
| Object Store | 对象存储 | 数据被切成固定大小的"对象"来存取,像一个个标准快递箱 |
- RADOS Cluster = 分布式集群 = 服务端
-
RADOS Cluster 本身就是由多台物理主机组成的
-
不是一台机器叫 RADOS,是这几台绑在一起才叫 RADOS Cluster
生产环境(≥3 台主机): 单节点实验(--single-host-defaults):
Ceph-201 Ceph-202 Ceph-203 Ceph-201(只有一台)
┌────────┐ ┌────────┐ ┌────────┐ ┌───────────────────┐
│ MON ✅️ │ │ MON ✅️ │ │ MON ✅️ │ │ MON ✅️ │
│ MGR ✅️ │ │ MGR │ │ MGR │ │ MGR ✅️ × 2 │
│ OSD.0 │ │ OSD.3 │ │ OSD.6 │ │ OSD.0 OSD.1 OSD.2 │
│ OSD.1 │ │ OSD.4 │ │ OSD.7 │ └───────────────────┘
│ OSD.2 │ │ OSD.5 │ │ OSD.8 │ ⚠️ 一台挂 = 全集群挂 ❌️
└────────┘ └────────┘ └────────┘ # 不适合生产环境
一台挂 → 另两台顶上 ✅️
📌 一句话:RADOS 是 Ceph 的唯一地基——无论上层是 RBD、CephFS 还是 RadosGW
数据最终都变成"对象"沉到 RADOS 里,再由它分发到各台机器的磁盘上
Ceph 架构全景:工具 → 接口 → 集群
Ceph 整个体系就三层——从你敲的命令,到程序调用的接口,到底层真正存数据的集群:
┌── 工具层:你在终端敲的命令 ──┐
│ │
rbd ceph fs radosgw-admin ceph
(块设备命令) (文件系统命令) (对象网关命令) (集群管理命令)
│ │ │
▼ ▼ ▼
┌── 接口层:三种存储入口 ──┐
│ │
RBD CephFS RadosGW
(块设备接口) (文件系统接口) (对象网关接口)
│ │ │
└───────────────┴───────────────┘
│
════════════════════╪════════════════
▼
RADOS Cluster = 分布式集群 = 服务端
┌───────┐ ┌───────┐ ┌───────┐
│ MON │ │ MON │ │ MON │ ← 大脑:管地图
└───────┘ └───────┘ └───────┘
┌───────┐
│ MGR │ ← 副手:管监控
└───────┘
┌───────┐ ┌───────┐ ┌───────┐
│ OSD.0 │ │ OSD.1 │ │ OSD.2 │ ← 仓库:真存数据
│ /sdb │ │ /sdc │ │ /sdd │
└───────┘ └───────┘ └───────┘
📌 三层角色:
| 层 | 是什么 | 谁在用 | 举例 |
|---|---|---|---|
| 工具层 | 命令行可执行文件 | 运维/开发人员手工敲 | rbd create、ceph fs ls、radosgw-admin user create |
| 接口层 | 三种存储入口 | 应用程序通过代码调用 | RBD(块)、CephFS(文件)、RadosGW(对象) |
| 集群层 | 服务端进程的集合 | 接口层把数据交给它 | MON + MGR + OSD + MDS(可选) |
💡 类比: - 工具层 = ATM 机的触摸屏——你用手指点它 - 接口层 = ATM 机内部的银行系统——屏上的操作转成后台调用 - 集群层 = 银行金库——钱真正存放的地方
📌 librados 为什么不在接口层:它不是独立的存储类型(你不能说"我用 librados 存储")
- 而是 RBD 和 RadosGW 底层共用的 C 语言原生库
三种存储类型
| 存储类型 | 接口(接口层) | 工具(工具层) | 依赖关系 | 通俗理解 | 典型用途 |
|---|---|---|---|---|---|
| 块存储 | RBD | rbd |
依赖 librados | 虚拟硬盘,能格式化、分区、挂载 | 虚拟机磁盘、数据库 |
| 文件存储 | CephFS | ceph fs |
不依赖 librados | 共享文件夹,多台机器同时挂载 | 文件共享、日志存储 |
| 对象存储 | RadosGW | radosgw-admin |
依赖 librados | HTTP/HTTPS API,适合非结构化数据 | 图片/视频云存储 |
💡 关键区别:
- RadosGW:基于 RESTful 风格提供跨互联网的云存储服务
- 里面的对象和 Ceph 内部的对象(固定大小存储块,基于 RPC 协议)不是一回事
- RBD:将 Ceph 集群的存储空间模拟成独立块设备,依赖 Linux 内核的 librbd 模块
- CephFS:和 librados 是同级组件,但使用热度比 RadosGW 和 RBD 低
📌 librados 的特殊地位:
RBD 和 RadosGW 底层都调用 librados,但 CephFS 不走这条路:
RBD ──────→ librados ──→ RADOS Cluster
RadosGW ──→ librados ──→ RADOS Cluster
CephFS ─────────────────→ RADOS Cluster (直接和 MDS / OSD 通信)
RADOS Cluster = 分布式集群 = 服务端
librados 是 Ceph 的"母语"——其他接口要么基于它,要么绕过它直接说方言
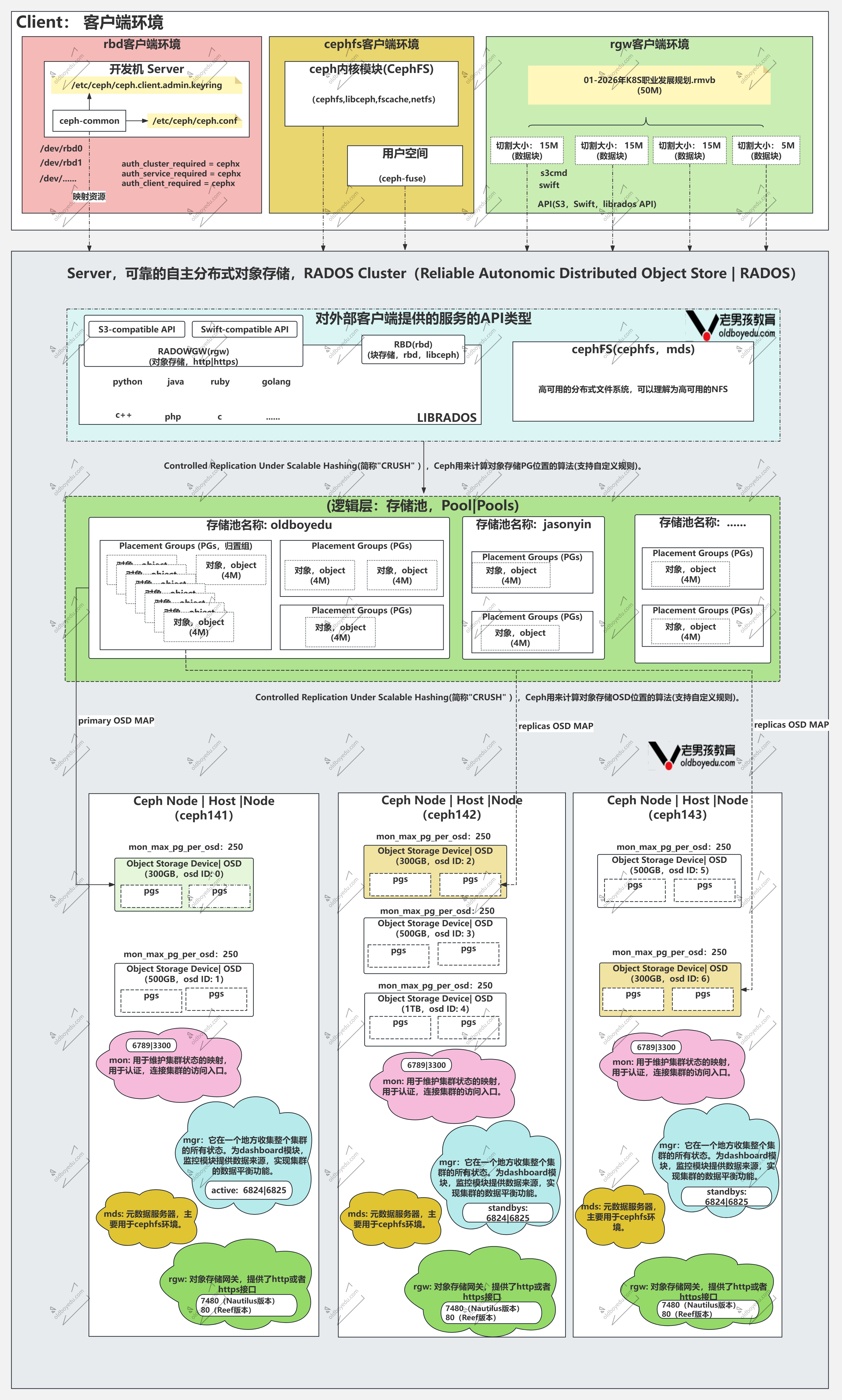
📌 核心要点:
- 无论你用哪种工具、哪种接口,最终数据都会被写入 RADOS Cluster(分布式集群)
- 每种客户端类型都有自己的存储池(Pool)资源
- 这句话的核心意思是:不同存储类型的"数据地盘"是分开的
"类比理解"
一个 RADOS Cluster 就像一栋商场大楼:
RADOS Cluster(商场)
├── Pool A(RBD 专区) → 只放虚拟硬盘的"扇区数据"
├── Pool B(CephFS 专区) → 只放共享文件夹的"文件+目录信息"
├── Pool C(RadosGW 专区)→ 只放云存储的"图片/视频对象"
└── Pool D(.mgr 系统池) → 只放集群自己的"内部账本"
# 初始化集群后只有一个 .mgr 系统池
✅️ 每个 Pool 有自己独立的配置——副本数、PG 数量、CRUSH 规则——互不干扰
===========================
为什么不能混用❓️
1.RBD 存的是扇区块(像硬盘的 0/1 二进制块)
2.CephFS 存的是文件 + 目录树(像文件夹结构)
3.RadosGW 存的是S3 对象 + 元数据(像云存储的 Key-Value)
✅️ 数据格式完全不同,所以每种类型必须有自己的 Pool
💡 就像商场里服装店和餐厅不能共用同一个铺位
📌 一句话总结
- 每种客户端类型都有自己的存储池
- 你用 RBD 就建 RBD 的池,用 CephFS 就建 CephFS 的池,各有各的地盘,互不串门
CRUSH 算法详解
CRUSH = Controlled Replication Under Scalable Hashing
- 可控的、可扩展的、基于哈希的副本分布算法
- CRUSH 算法 是 Ceph 内部数据对象存储路由的算法,它没有中心节点(无元数据服务器)
🧱 通俗理解:
传统存储(比如 HDFS)的做法:
-
搞一个 NameNode(元数据服务器),里面记着"文件A → 块1在机器3、块2在机器5"
-
客户端每次读写都要先问它
Ceph 的做法:不搞中心索引 --> 客户端自己算位置(去中心化)
传统 HDFS: Ceph CRUSH:
客户端 客户端
│ "文件A存哪?" │ "我自己算!"
▼ │
NameNode ──→ "机器3和机器5" │ 对象名 + CRUSH Map
│ │ ↓ 哈希计算
▼ │ OSD.3 + OSD.7 + OSD.12
机器3、机器5 ▼
直接找 OSD.3 写数据
💡 核心思想:CRUSH 就是一个伪随机哈希函数——给定"对象名字"和"集群地图",算出"应该存到哪几块盘"
| 对比维度 | 传统元数据服务器(HDFS NameNode) | Ceph CRUSH |
|---|---|---|
| 数据寻址 | 查表——问中心节点 | 计算——客户端自己算 |
| 中心节点 | 有(单点瓶颈、单点故障) | 无(去中心化) |
| 扩展性 | 受限于 NameNode 内存 | 理论上无限 |
| 节点增减 | 需要大规模重新平衡 | 只迁移受影响的 PG,其余不动 |
| 故障影响 | NameNode 一挂 → 所有 I/O 立刻停 | Monitor 不在数据路径上(门口保安) 短期:已连接客户端仍可读写 长期:无法认证新连接,集群最终不可用 |
🧱 为什么 Monitor 挂了"短期能读、长期不行":
HDFS NameNode 是"必经之路": Ceph Monitor 是"门口保安":
客户端 客户端(缓存了地图)
│ 每次读写都得问 │ "我知道 OSD.3 在哪"
▼ ▼
NameNode ──→ 一挂全停 ❌️ OSD.3 ←── 直接通信,不经过 Monitor
✅️ Monitor 不在数据路径上
| 场景 | 还能不能? | 原因 |
|---|---|---|
| 部分 Monitor 挂(还有 quorum) | ✅ 完全正常 | 活着的 Monitor 继续服务,3个挂1个 --> 无所谓 |
| 全部 Monitor 挂 → 已连接客户端读写 | ✅ 短期能 | 客户端缓存了 OSD Map 和 CRUSH Map,知道数据在哪个 OSD,直接和 OSD 通信 |
| 全部 Monitor 挂 → 新建连接/打开新文件 | ❌ 不能 | 新客户端需要向 Monitor 认证身份、获取集群地图 |
| 全部 Monitor 挂 → 长时间运行 | ❌ 不能 | OSD Map 有过期时间,OSD 之间心跳也会断,集群最终停摆 |
📌 CRUSH 三个关键优势:
-
去中心化:客户端拿着 CRUSH Map(集群拓扑图),自己就能算出数据该存哪个 OSD,不需要每次问 Monitor
- 这就是"没有元数据服务器"的含义
-
故障域可控:你可以指定"同一份数据的 3 个副本必须分布在 3 台不同主机上"
- 这就是
type=host的作用
- 这就是
-
弹性伸缩:加减 OSD 时,CRUSH 只重新分配受影响的 PG(安置组),不是全量数据搬迁
📌 CRUSH Map 是什么❓️
CRUSH Map 就是"集群的地图"——它描述了: - 有多少台主机 - 每台主机上有多少块 OSD - OSD 的权重(容量越大的盘权重越高) - 故障域层级(root → host → osd)
客户端下载了这份地图,就不需要问别人了——所有位置计算都在本地完成
核心组件
🚢 ① OSD(Object Storage Device,对象存储守护进程,ceph-osd)
通俗解释:真正负责存数据的"仓库管理员",一块磁盘对应一个 OSD 守护进程,类似于 HDFS 的 DataNode
- 存储数据、处理数据复制、恢复、重新平衡
- 通过检查其他 OSD 的心跳向 Monitor 和 Manager 提供监视信息
- 负责守护程序和管理客户端之间的身份验证(基于 Cephx 协议)
- ❗️ 为了实现冗余和高可用,通常至少需要 3 个 OSD(默认数据副本是 3 个)
🧱 OSD 心跳互检——"不是 Monitor 挨个 ping,而是 OSD 互相盯着":
Monitor(大脑)
▲
"OSD.3 挂了!"
│
┌──────────┼──────────┐
│ │ │
OSD.0 ←──→ OSD.1 ←──→ OSD.2
│ 心跳 │ 心跳 │
└───────────┴──────────┘
-
每个 OSD 定期给其他 OSD 发心跳包
-
如果 OSD.0 发现 OSD.3 半天没回应,就主动上报 Monitor
-
Monitor 不需要自己扫描所有 OSD
类比:老师(Monitor)不需要挨个点名——同学们(OSD)互相看着,谁没来立刻有人举手报告
🧱 OSD 负责 Cephx 身份验证——"Monitor 发证,OSD 验票":
① 先去 Monitor 领"通行证"
客户端 ──────────────────────────> Monitor
│ "我是 client.admin,这是我的 key"
│ │
│ <────── 通行证(ticket)────────┘
│ Monitor 用密钥签名
│
│ ② 拿着通行证直接找 OSD
└────────────────────────────────> OSD.3
"我要写数据,这是我的通行证"
│
OSD 自己验票:
"签名是 Monitor 的❓️"
'没过期❓️权限够❓️'
│
▼
✅ 放行 / ❌ 拒绝
关键:Monitor 只负责签发通行证,不参与每一次数据读写——否则 Monitor 又变成瓶颈了
- OSD 是验票的——每一次客户端读写,OSD 都要查通行证是否有效,防止未授权的客户端偷数据
- 通行证是 Monitor 用密钥签名的,OSD 认得这个签名——不需要每次回头问 Monitor
📦 ② Monitor(监视器,ceph-mon)
通俗解释:集群的"大脑"和"元数据中心",维护整个集群的运行状态地图
- 维护 5 张映射表:Monitor Map、Manager Map、OSD Map、CRUSH Map、PG Map
- 负责集群成员管理和客户端认证
- ❗️ 至少需要 3 个 Monitor(高可用 + 负载均衡)
⚙️ ③ Manager(管理器,ceph-mgr)
通俗解释:Monitor 的"数据缓存副手"——它把查询类操作缓存下来,监控请求时能及时响应
- Ceph 早期版本没有 mgr 组件,mon 每次查询都实时读取,代价高昂
- L 版本引入 mgr,还托管基于 Python 的插件和 Rest API
- ❗️ 高可用通常至少需要 2 个 Manager
🧱 Manager 缓存了什么——和 Dashboard 的关系:
浏览器打开 Dashboard(https://Ceph-201:8443)
│
▼
Manager ←── 提前从集群各处收集并缓存:
│
├── 集群健康状态(HEALTH_OK / WARN / ERR)
├── OSD 列表、状态、容量、延迟
├── MON 列表、quorum 情况
├── PG 状态(active+clean / degraded / ...)
├── 性能图表数据(IOPS、吞吐量、延迟曲线)
├── Dashboard 配置(你改过的密码、告警阈值...)
└── 设备健康信息(SMART 数据、磁盘温度...)
简单概括: '存设备健康+数据、性能指标、Dashboard 配置等"内部账本"'
这些数据存在哪❓️
→ Manager 把上述数据持久化到 .mgr 存储池(系统池,bootstrap 时自动创建)
→ 这样 Manager 重启后配置不丢,Dashboard 刷新时秒出数据
❌️ Manager 不存用户数据(你的 RBD 块、CephFS 文件、RadosGW 对象)
✅️ 它只管"集群自己的内部账本和监控数据"
📌 通俗类比:
Monitor 是"公司档案室"(存地图和花名册)
Manager 是"运营大屏"(Dashboard)的后台
- 它提前把各项指标算好缓存起来,你打开网页时不用现场去每个部门问一遍
🗂️ ④ MDS(MetaData Server,元数据服务器,ceph-mds,可选组件)
通俗解释:对应 CephFS 文件系统的"目录索引",类似于 HDFS 的 NameNode——找文件时不用扫描所有 OSD
- 存储 CephFS 的元数据(文件名、目录结构、权限)
- 仅在使用 CephFS 时需要,RBD 和 RadosGW 不需要
- 从严格意义上来讲,MDS 只能算作构建于 RADOS 之上的文件存取接口,而非基础组件
- ❗️ 如果使用 CephFS,建议部署多个 MDS 以防单点故障
🔹 ⑤ RGW(对象存储网关,可选组件)
用于对象存储系统,需要启用相关组件模块
📋 ⑥ Pool & PG(存储池 & 安置组,抽象概念)
通俗解释:
- Pool:数据的逻辑分区
- 一个 Ceph 集群可以有多个 Pool,每个 Pool 还可以划分多个 namespace
- PG(Placement Group):Pool 内部的逻辑分组
- 数据通过 CRUSH 算法映射到具体 OSD 时,以 PG 为单位
[!TIP]
Pool 就是 PG 的容器,PG 是数据分布的"最小单位"
数据存储流程
用一个具体例子走一遍:把一张 100MB 的照片存进 Ceph
┌───────────────────────────────────────────────┐
│ Step 1:切块 │
│ │
│ 100MB 照片 │
│ │ │
│ ▼ │
│ ┌──────┐┌──────┐┌──────┐ ┌──────┐ │
│ │ 4MB ││ 4MB ││ 4MB │ ... │ 4MB │ │
│ │ obj1 ││ obj2 ││ obj3 │ ×25 │ obj25│ │
│ └──────┘└──────┘└──────┘ └──────┘ │
│ │
│ Ceph 的对象固定 4MB,100MB → 切成 25 个对象 │
│ │
│ 如果只有 10MB: │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │ 4MB │ │ 4MB │ │ 4MB │ │
│ │ obj1 │ │ obj2 │ │ obj3 │ │
│ └──────┘ └──────┘ └──────┘ │
│ 不足 4MB 也按 4MB 分配(2MB 数据 + 2MB 空白) │
│ '对象大小固定 4MB,不够就补齐' │
│ │
└───────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Step 2:对象→Pool→PG(CRUSH 计算) │
│ │
│ 以 obj1 为例 --> 每个对象在 RADOS 中有唯一的名字 │
│ │
│ "对象名"(如 rbd_data.1032.0001) │
│ + │
│ CRUSH Map │
│ │ (集群地图:几台主机、几块盘、权重多少) │
│ ▼ 'CRUSH 伪随机哈希' │
│ 命中 Pool 下的某个 PG → 例如 PG.7 │
│ │
│ 25 个对象被均匀哈希到 Pool 下的各 PG 中 │
│ '一个 PG 里可以存放多个对象' │
│ Pool 是 PG 的容器,PG 是数据分布的"最小单位" │
└──────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Step 3:PG→OSD(副本落地) │
│ │
│ PG.7 要做 3 个副本(Pool 的 size=3): │
│ │
│ PG.7 │
│ │ │
│ ▼ 'CRUSH 再次计算'(故障域 = host) │
│ │ │
│ ├─→ 副本① → Ceph-201 的 osd.1 │
│ ├─→ 副本② → Ceph-202 的 osd.4 │
│ └─→ 副本③ → Ceph-203 的 osd.7 │
│ '三台不同主机' │
│ obj1 最终变成 3 份,落在 3 台不同机器的磁盘上 │
└─────────────────────────────────────────────┘
📌 三个关键角色:
| 角色 | 是什么 | 为什么需要它 |
|---|---|---|
| Object | 4MB 固定大小的数据块 | 统一大小,方便管理和分布 |
| PG | Pool 内的逻辑分组 | 海量对象 → 少量 PG → 几块 OSD PG 做聚合收敛:百万对象只需几百个 PG 加减 OSD 时只搬 PG,不搬海量对象 |
| CRUSH | 决定"去哪"的算法 | 在数据落地过程中用了两次:① 对象名→PG;② PG→OSD |
🧱 CRUSH 发挥了两次作用:
对象名 ──CRUSH①──→ PG.7 ──CRUSH②──→ osd.1 / osd.4 / osd.7
"去哪个 PG?" "这个 PG 的 3 个副本放哪 3 块盘?"
第一次负责逻辑分组(对象归哪个 PG)
第二次负责数据落盘(PG 的副本落哪几块盘)
两段分工不同,但用的都是同一套 CRUSH 算法
🧱 PG 的数量远小于对象的数量——这才是 PG 存在的意义:
一个 Pool 里的数量对比:
对象:几百万个(甚至上亿) ← 海量
│ 'CRUSH 哈希收敛'
▼
PG:几百个(通常 32 ~ 1024) ← 少量
│ 'CRUSH 再计算'
▼
OSD:几十块盘 ← 更少
- PG 做的是聚合收敛——不是一对一映射
- 如果每个对象对应一个 PG,那 PG 就没有存在的必要了
✅️ 一个 PG 里可以存放多个对象:
PG.7(一个 PG)
├── obj1(4MB)
├── obj8(4MB)
├── obj15(4MB)
├── obj22(4MB)
├── ...(成千上万个对象)
└── objN(4MB)
CRUSH 把对象均匀哈希到各 PG → 每个 PG 里装了大量对象
迁移时以 PG 为单位搬 → 一次搬"一筐对象",而不是一个一个搬
📌 一句话总结:文件 → 切成对象 → CRUSH 算 PG → PG 分发到 OSD → 存 3 份到不同主机
BlueStore 存储引擎
BlueStore 是 OSD 内部的存储引擎——决定数据最终以什么方式写到磁盘上
🧱 通俗理解:
OSD 收到一个对象后,怎么把它存到磁盘❓️ --> 这就靠存储引擎
Ceph 经历过一次大换血:
旧方案:FileStore 新方案:BlueStore(v12.2.z 起默认)
对象 对象
│ │
▼ ├──> 数据 ──> 直接写裸块设备(/dev/sdb)
Journal(日志盘) │
│ ← 先写一份到这里(第 1 次写) │
▼ ├──> 元数据 ──> Key-Value 数据库
XFS 文件系统 │ "对象名叫啥、存在磁盘哪个位置..."
│ ← 再从 Journal 搬到这(第 2 次写) │
▼ │
裸块设备 └──> 都在同一块盘上,没有中间商
问题:
1.每笔数据写两遍 → 慢!
2.XFS 这层本身也有开销 → 又慢一点!
# 依赖 XFS 文件系统
| 对比 | FileStore(旧) | BlueStore(新) |
|---|---|---|
| 写数据 | 先写 Journal → 再搬 XFS → 再落盘(写两次) | 直接写裸块设备(写一次) |
| 元数据 | 靠 XFS 文件系统管理 | 内建 RocksDB(Key-Value 数据库),自己管 |
| 依赖 | 依赖 XFS 文件系统层 | 不依赖任何文件系统,直接在裸盘上存储 |
| 快满时 | 性能陡降 | 几乎不降 |
| 小随机写 | 慢 | 快(RocksDB 优化) |
| 额外机制 | 无 | 支持 COW(写时复制),RBD 快照/克隆更高效 |
- FileStore 是"先写草稿再誊写",BlueStore 是"一笔写成"
- 少了一道工序,性能自然更好
📌 RocksDB 是什么:一个轻量级的嵌入式键值(Key-Value)数据库(Facebook 开源)
- BlueStore 用它来存元数据——"对象 A 存在磁盘偏移量 0x1234 处,长度 4MB"
- 读写数据前先查 RocksDB,找到位置后直接操作裸盘
二、Ceph 高可用集群部署
部署工具概览
| 部署工具 | 特点 | 推荐度 |
|---|---|---|
| cephadm | 类似 kubeadm,部署服务非常方便,容器化部署 | ⭐⭐⭐⭐⭐ |
| ceph-deploy | 原生工具,仅依赖 SSH + sudo + Python | ⭐⭐(已丢弃) |
| ceph-ansible | 基于 Ansible playbook | ⭐⭐⭐⭐ |
💡 推荐使用 cephadm:与 k8s 的 kubeadm 一样好用,基于容器化部署,官方主推
Ceph 版本说明
x.0.z → 0 --> 开发版本(内部测试)
x.1.z → 1 --> 测试版本(开发人员测试)
x.2.z → 2 --> 稳定版本(✅️ 生产环境推荐)
'x --> 大版本'
'z --> 小版本'
示例: 20.2.1 (Tentacle) 为稳定版本
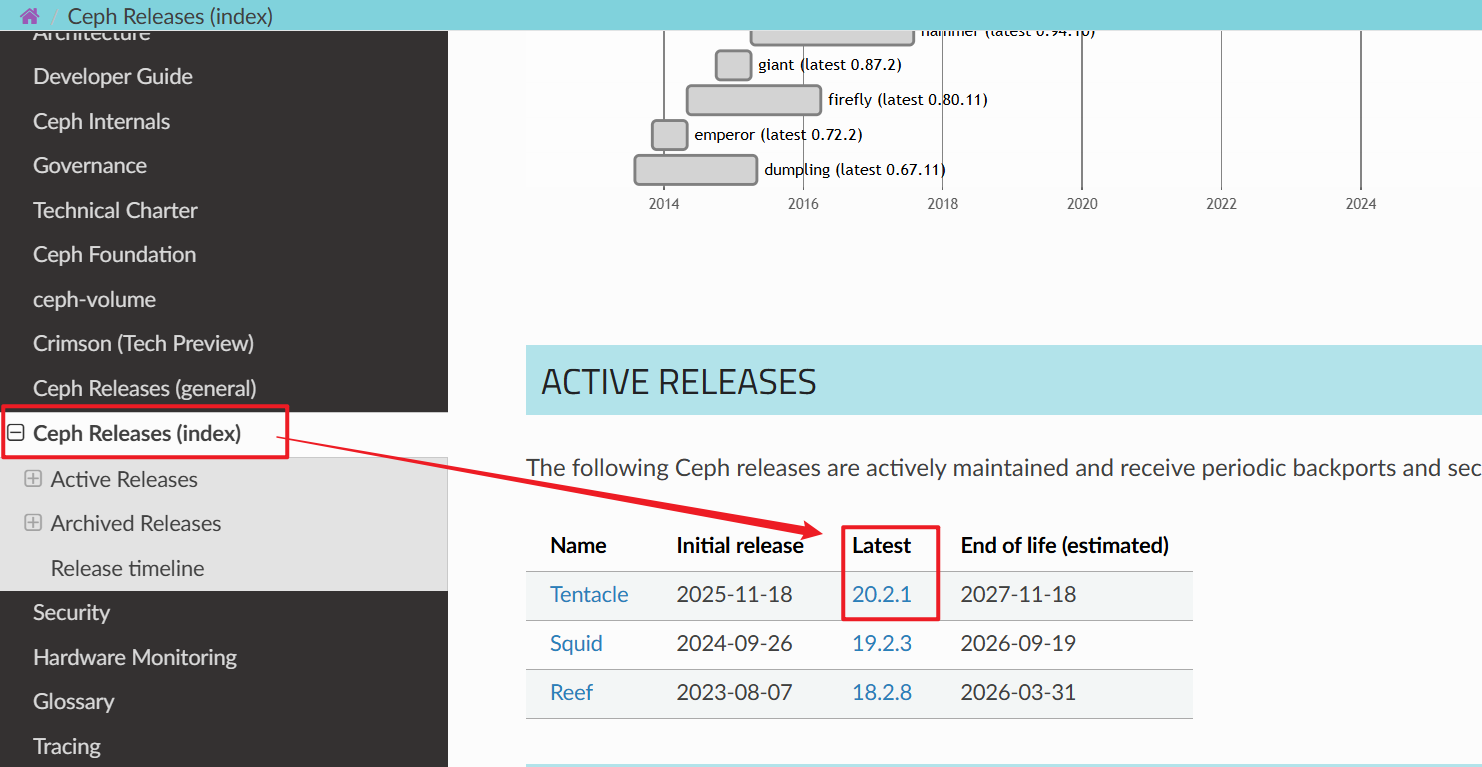
- Ceph Releases (index)
- 时刻关注版本变换
三、cephadm 快速部署实战
环境准备
官方前提条件
- Python 3
- Systemd
- Podman or Docker for running containers
- Time synchronization (such as Chrony or NTP)
- LVM2 for provisioning storage devices
集群节点规划(3 节点)
| 主机 | IP | CPU | 内存 | 磁盘设备 |
|---|---|---|---|---|
| Ceph-201 | 10.0.0.201 | 2C | 4G | /dev/sdb (300G), /dev/sdc (500G), /dev/sdd (1024G==1T) |
| Ceph-202 | 10.0.0.202 | 2C | 4G | /dev/sdb (300G), /dev/sdc (500G), /dev/sdd (1024G==1T) |
| Ceph-203 | 10.0.0.203 | 2C | 4G | /dev/sdb (300G), /dev/sdc (500G), /dev/sdd (1024G==1T) |
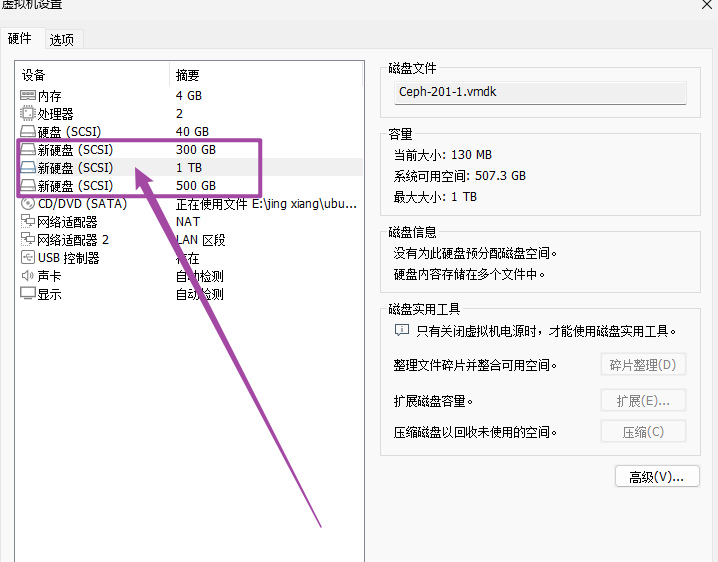
✅️ 我是开机添加的, "重启生效"
'查看磁盘设备是否就绪'
root@Ceph-201 ~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 40G 0 disk
|-sda1 8:1 0 1M 0 part
|-sda2 8:2 0 2G 0 part /boot
|-sda3 8:3 0 38G 0 part
└─-ubuntu--vg-ubuntu--lv 252:0 0 30G 0 lvm /
sdb 8:16 0 300G 0 disk # ← 待加入 Ceph 的数据盘
sdc 8:32 0 500G 0 disk # ← 待加入 Ceph 的数据盘
sdd 8:48 0 1T 0 disk # ← 待加入 Ceph 的数据盘
sr0 11:0 1 2.6G 0 rom
"sdb/sdc/sdd 三块裸盘无分区无挂载,满足加入 Ceph 的条件"
基础环境配置
1)设置时区(所有节点)
root@Ceph-201 ~# timedatectl status | grep zone
Time zone: Asia/Shanghai (CST, +0800)
root@Ceph-201 ~# timedatectl set-timezone Asia/Shanghai
root@Ceph-201 ~# ll /etc/localtime
lrwxrwxrwx 1 root root 33 May 16 09:38 /etc/localtime -> /usr/share/zoneinfo/Asia/Shanghai
2)安装 Docker 环境(所有节点)
root@Ceph-201 ~# ls
autoinstall-docker.zip
root@Ceph-201 ~# unzip autoinstall-docker.zip
root@Ceph-201 ~# chmod +x install-docker.sh
root@Ceph-201 ~# ./install-docker.sh i
root@Ceph-201 ~# scp -O autoinstall-docker.zip root@10.0.0.202:/root/
autoinstall-docker.zip 100% 96MB 108.2MB/s
# -O 参数会告诉 scp 使用旧版的 SCP 协议进行文件传输,而不是默认的 SFTP 协议
root@Ceph-201 ~# scp -O autoinstall-docker.zip root@10.0.0.203:/root/
'把tar包拷贝过去'
# 另外两台也要进行安装
3)添加 hosts 解析(所有节点)
root@Ceph-201 ~# cat >> /etc/hosts <<EOF
10.0.0.201 Ceph-201
10.0.0.202 Ceph-202
10.0.0.203 Ceph-203
EOF
4)集群时间同步(Ubuntu 系统可跳过)
5)关机拍快照【强烈推荐】
root@Ceph-201 ~# init 0
# 快照可以让你在部署失败时快速回滚
初始化 Ceph 集群
- 下载并安装 cephadm
1)下载 cephadm(选择与目标版本一致)
root@Ceph-201 ~# CEPH_RELEASE=20.2.1
root@Ceph-201 ~# curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
'建议用浏览器去提前下载安装'
root@Ceph-201 ~# ls
cephadm
2)添加到 PATH
root@Ceph-201 ~# chmod +x cephadm
'下载下来的是二进制执行文件644'(不保留x权限)
root@Ceph-201 ~# mv cephadm /usr/local/bin/
root@Ceph-201 ~# ls /usr/local/bin/cephadm
/usr/local/bin/cephadm
root@Ceph-201 ~# cephadm version
# 验证版本
cephadm version 20.2.1 (6a49aff47758778a5f5951e731d437c317f72fb2) tentacle (stable)
'版本号确认无误 ✅️'
- 必要镜像拉取
'提前拉取 Ceph 所需镜像(避免初始化时从外网拉取失败)'
root@Ceph-201 ~# docker pull quay.io/ceph/ceph:v20
root@Ceph-201 ~# docker pull quay.io/ceph/grafana:12.2.0
root@Ceph-201 ~# docker pull quay.io/prometheus/prometheus:v3.6.0
root@Ceph-201 ~# docker pull quay.io/prometheus/node-exporter:v1.9.1
root@Ceph-201 ~# docker pull quay.io/prometheus/alertmanager:v0.28.1
'因为这些镜像没在Docker Hub上, 所以拉取镜像还是很轻松的'
root@Ceph-201 ~# docker images
quay.io/ceph/ceph:v20 0bae386bc859 2.15GB
quay.io/ceph/grafana:12.2.0 74144189b384 974MB
quay.io/prometheus/alertmanager:v0.28.1 27c475db5fb1 110MB
quay.io/prometheus/node-exporter:v1.9.1 d00a542e409e 40.8MB
quay.io/prometheus/prometheus:v3.6.0 76947e7ef22f 440MB
# 5 个核心镜像:ceph + grafana + prometheus + node-exporter + alertmanager
'save导出 & load导入别的节点'
root@Ceph-201 ~# docker save quay.io/ceph/ceph:v20 > ceph-v20.tar.gz
root@Ceph-201 ~# docker save quay.io/ceph/grafana:12.2.0 > grafana-12.2.0.tar.gz
root@Ceph-201 ~# docker save quay.io/prometheus/alertmanager:v0.28.1 > alertmanager-v0.28.1.tar.gz
root@Ceph-201 ~# docker save quay.io/prometheus/node-exporter:v1.9.1 > node-exporter-v1.9.1.tar.gz
root@Ceph-201 ~# docker save quay.io/prometheus/prometheus:v3.6.0 > prometheus-v3.6.0.tar.gz
root@Ceph-201 ~# ls *.tar.gz | xargs -n 1
alertmanager-v0.28.1.tar.gz
ceph-v20.tar.gz
grafana-12.2.0.tar.gz
node-exporter-v1.9.1.tar.gz
prometheus-v3.6.0.tar.gz
root@Ceph-201 ~# ls *.tar.gz | xargs -i scp -O {} root@10.0.0.202:/home/test
root@Ceph-201 ~# ls *.tar.gz | xargs -i scp -O {} root@10.0.0.203:/home/test
# 别的节点
root@Ceph-202 ~# ls /home/test/
alertmanager-v0.28.1.tar.gz
root@Ceph-202 ~# cd /home/test/
root@Ceph-202 test# for i in `ls`; do docker load -i $i;done
'另一台也一样'
root@Ceph-203 test# docker images
quay.io/ceph/ceph:v20
quay.io/ceph/grafana:12.2.0
...........xxxxxxxx
初始化集群
root@Ceph-201 ~# cephadm bootstrap \
--mon-ip 10.0.0.201 \
--cluster-network 10.0.0.0/24 \
--allow-fqdn-hostname \
--skip-pull
'cephadm bootstrap 是 Ceph 集群初始化的核心命令'
📌 参数说明:
| 参数 | 作用 |
|---|---|
--mon-ip 10.0.0.201 |
指定 Monitor 监听 IP |
--cluster-network 10.0.0.0/24 |
集群内部通信网络(OSD 间数据复制走此网) |
--allow-fqdn-hostname |
允许使用主机名而非仅 IP |
--skip-pull |
跳过镜像拉取(已提前导入) |
🔹 bootstrap 常用可选参数补充
| 参数 | 作用 |
|---|---|
--registry-url=xxxx |
指定私有镜像仓库地址 |
--registry-username=xxxx |
私有仓库用户名 |
--registry-password=xxx |
私有仓库密码 |
--initial-dashboard-password=xxx ✅️ |
预设 Dashboard 密码 |
--dashboard-password-noupdate ✅️ |
禁止首次登录强制修改密码 |
--single-host-defaults |
单节点部署优化(见下方实验) |
Verifying podman|docker is present...
...........
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr is available
Ceph Dashboard is now available at:
URL: https://Ceph-201:8443/ <--'域名访问'(导入Windows中hosts表)
User: admin <--"用户名"
Password: twt8hvj9t0 <--"密码"(随机生成)
💡 Bootstrap 做了什么?
① 生成了集群 FSID(唯一标识)
② 在本地主机上为新集群创建一个 Monitor(监听 10.0.0.201:6789) 和一个 Manager 守护程序
③ 为 Ceph 集群生成一个新的 SSH 密钥,私钥自己拿着(存在 Ceph 内部)
- 👆 并将公钥添加到 root 用户的
/root/.ssh/authorized_keys文件中(方便连自身)④ 将公钥副本写入
/etc/ceph/ceph.pub(用于分发)⑤ 将最小配置文件写入
/etc/ceph/ceph.conf(与 Ceph 守护程序通信所必需的)⑥ 将
client.admin管理(特权)密钥副本写入/etc/ceph/ceph.client.admin.keyring⑦ 将
_admin标签添加到引导主机
- 👆 默认情况下,任何具有此标签的主机都会获得 ceph.conf 和 keyring(管理员密钥环)的副本
1)SSH 密钥与 authorized_keys(为什么内容一模一样?)
root@Ceph-201 ~# cat /root/.ssh/authorized_keys
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIMK+kon/b+d4oV1PQNY4AKhq5R9M17zm18uLv//0/4N8 ceph-fdc2219c-5344-11f1-8042-000c2990a57e
=======================不同的文件
root@Ceph-201 ~# cat /etc/ceph/ceph.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIMK+kon/b+d4oV1PQNY4AKhq5R9M17zm18uLv//0/4N8 ceph-fdc2219c-5344-11f1-8042-000c2990a57e
=======================
─── 通俗解释 ───
SSH 密钥对 = 私钥 + 公钥
- 私钥(自己留着,不公开) → Bootstrap 生成了,存在 Ceph 内部
- 公钥(可以到处分发) → 写入 /etc/ceph/ceph.pub
/root/.ssh/authorized_keys 是什么❓️
→ 这是 SSH 的"访客白名单":谁的公钥在里面,谁就能"免密登录"这台机器
=======================
为什么两个文件内容一样?
Bootstrap 拿同一把公钥做了两件事:
① 把公钥"贴到"自己的 authorized_keys 文件里
→ 让 Ceph-201 自己能 SSH 免密连自己(后续编排时 master 需要连自身)
② 把公钥保存到 /etc/ceph/ceph.pub
→ 以后用 ssh-copy-id -i /etc/ceph/ceph.pub 分发给其他节点
→ 其他节点收到这把公钥,也会把它写入自己的 authorized_keys
→ 这样 Ceph-201 就能免密 SSH 到所有节点,完成集群的编排调度
📌 一句话:ceph.pub 是钥匙的"公钥副本",authorized_keys 是"允许用这把钥匙的人进来"
✅️ 两者内容相同,因为本质上是同一把公钥
2)最小配置文件
root@Ceph-201 ~# cat /etc/ceph/ceph.conf
# minimal ceph.conf for fdc2219c-5344-11f1-8042-000c2990a57e
[global]
fsid = fdc2219c-5344-11f1-8042-000c2990a57e # ← 集群唯一身份证号(UUID)
mon_host = [v2:10.0.0.201:3300/0,v1:10.0.0.201:6789/0]
=======================
─── 通俗解释 ───
fsid(集群 ID):
1.就像每个人的身份证号,全球唯一,用来区分不同的 Ceph 集群
2.当你管理多个集群时,就是靠 fsid 来区分"你在操作哪一个集群"
=======================
mon_host(Monitor 地址列表):
告诉客户端:集群的大脑(Monitor)在哪里?
格式:[v2:IP:3300/0, v1:IP:6789/0]
- v2(msgr2 协议):端口 3300,新版高性能通信协议,支持加密
- v1(msgr1 协议):端口 6789,老版协议,向后兼容
"两个协议地址都写上,新旧客户端都能连"
=======================
为什么叫"最小配置"❓️
① fsid → 知道你是谁(不能连错集群)
就像你去公司报到,只需要知道"公司名称"和"公司地址"
② mon_host → 知道大脑在哪里(去哪报到)
其他所有信息(OSD 在哪、数据怎么分布…)都由 Monitor 动态告诉你
3) 管理员密钥环(keyring)
root@Ceph-201 ~# cat /etc/ceph/ceph.client.admin.keyring
[client.admin] # ← 用户名:client.admin(管理员账号)
key = AQBh9wtq2sSYJRAAweHsVl4OjRia0jObKVHapA== # ← 管理员的"密码"
caps mds = "allow *" # 对 MDS 的权限: * = 所有操作
caps mgr = "allow *" # 对 Manager 的权限: * = 所有操作
caps mon = "allow *" # 对 Monitor 的权限: * = 所有操作
caps osd = "allow *" # 对 OSD 的权限: * = 所有操作
=======================
─── 通俗解释 ───
keyring(密钥环)是什么❓️
就是 Ceph 的"用户名+密码+权限"文件
类似 MySQL 的 user@host 认证,或 Linux 的 /etc/shadow
MySQL 客户端连接 ` mysql -u root -p `
# 你向 MySQL 服务端证明"我是 root"
Ceph 客户端连接 ` ceph -s ` ---> 背后读取 client.admin keyring
# ceph 命令行工具向 Monitor(mon_host 指定的地址)证明"我是 admin"
=======================
[client.admin] → 用户名
这是 Ceph 的"root 账号",拥有集群的绝对控制权
类比:Linux 的 root、MySQL 的 root@localhost
key = AQBh... → 密码(经过 base64 编码的密钥)
这是 client.admin 的认证密钥,不是人类可读的密码,而是加密密钥
客户端出示 key → Monitor 验证 → 通过后发放 session ticket
"普通客户端(只想挂个 RBD 硬盘) --> 创建一个权限受限的普通账号"
=======================
caps(capabilities,权限)→ 能做什么
每个组件都有独立的权限控制:
mds = CephFS 元数据服务器 → allow * = 可以读写所有文件系统操作
mgr = Manager → allow * = 可以访问监控和编排功能
mon = Monitor → allow * = 可以查看和修改集群状态
osd = OSD 数据守护进程 → allow * = 可以直接读写所有磁盘数据
4) 浏览器访问 Dashboard
URL: https://Ceph-201:8443/
# 用上面输出的 admin 用户名和初始密码登录即可
如果用主机名访问 Dashboard,需要修改 Windows 的hosts 解析记录
⚠️ 注意:首次登录 Dashboard 需要修改密码
配置 Ceph 集群管理命令
方式一:宿主机直接安装(推荐)
1)安装 ceph 通用工具包
root@Ceph-201 ~# apt update
root@Ceph-201 ~# apt -y install ceph-common
# 所有主机节点都装一下
2)测试使用
root@Ceph-201 ~# ceph version
ceph version 20.2.1 (6a49aff47758778a5f5951e731d437c317f72fb2) tentacle (stable)
root@Ceph-201 ~# ceph -s
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_WARN
# 还没加 OSD,所以健康状态为 WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum Ceph-201 (age 7m) [leader: Ceph-201]
mgr: Ceph-201.cxdvrq(active, since 7m)
osd: 0 osds: 0 up, 0 in
# 还没有 OSD
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
方式二:基于容器管理
1)启动 cephadm shell(本质是启动了一个临时容器)
root@Ceph-201 ~# cephadm shell
Inferring fsid fdc...xxx
root@Ceph-201:/# ceph -s
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
...
============================
# 新开一个终端
root@Ceph-201 ~# docker ps -l
IMAGE COMMAND CREATED STATUS
0bae386bc859 "bash" About a minute ago Up About a minute
============================
root@Ceph-201:/# exit
exit
'exit退出shell后,容器随即自动删除'
2)非交互式执行命令(执行完自动退出容器)
'用 -- 分隔,后面跟要执行的命令,适合脚本和快速查看'
root@Ceph-201 ~# cephadm shell -- ceph -s
Inferring fsid ...
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
...
3)多集群环境指定参数
'单集群环境 --> 参数可自动添加,多集群需显式指定'
root@Ceph-201 ~# cephadm shell --fsid <fsid> -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
✅️ 明确指定集群 fsid、最小配置文件、keyring(管理员密钥环)路径
📌 关键点:cephadm shell 本质是启动一个临时容器,退出即删除
添加主机到集群
'在 Ceph-201 节点上操作'
1)查看现有集群主机
root@Ceph-201 ~# ceph orch host ls
HOST ADDR LABELS STATUS
Ceph-201 10.0.0.201 _admin
1 hosts in cluster
2)把 SSH 公钥分发到其他节点
root@Ceph-201 ~# ssh-copy-id -f -i /etc/ceph/ceph.pub Ceph-202
-f # 参数用于强制复制
-i # 指定密钥
Number of key(s) added: 1
root@Ceph-201 ~# ssh-copy-id -f -i /etc/ceph/ceph.pub Ceph-203
3)添加主机到集群
root@Ceph-201 ~# ceph orch host add Ceph-202 10.0.0.202
Added host 'Ceph-202' with addr '10.0.0.202'
root@Ceph-201 ~# ceph orch host add Ceph-203 10.0.0.203
Added host 'Ceph-203' with addr '10.0.0.203'
4)验证集群节点列表
root@Ceph-201 ~# ceph orch host ls
HOST ADDR LABELS STATUS
Ceph-201 10.0.0.201 _admin
Ceph-202 10.0.0.202
Ceph-203 10.0.0.203
3 hosts in cluster
✅️ 3 个节点全部加入集群
四、添加 OSD 设备
OSD 加入条件
⚠️ 一个设备想要加入 Ceph 集群,必须满足 3 个条件:
(1)设备未被使用(无分区、无文件系统、没有被 LVM 占用、当前未挂载)
(2)设备的存储大小必须大于 5GB
(3)需要等待 30s~3min 才能在 ceph orch device ls 中看到设备
'ceph orch device ls --refresh'
✅️ --refresh 强扫,比干等 agent 周期扫描快
'绕开缓存直接触发一次新扫描'
查看可用设备
1)查看集群可用的设备
root@Ceph-201 ~# ceph orch device ls
✅️ 优先加 --refresh 强扫选项
HOST PATH TYPE SIZE AVAILABLE
Ceph-201 /dev/sdb hdd 300G Yes 15m ago
Ceph-201 /dev/sdc hdd 500G Yes 15m ago
Ceph-201 /dev/sdd hdd 1024G Yes 15m ago
Ceph-201 /dev/sr0 hdd VMware..xxx space (<5GB) # ← 光驱,<5GB,不可用
Ceph-202 /dev/sdb hdd 300G Yes 13m ago
Ceph-202 /dev/sdc hdd 500G Yes 13m ago
Ceph-202 /dev/sdd hdd 1024G Yes 13m ago
Ceph-202 /dev/sr0 hdd VMware..xxx space (<5GB)
Ceph-203 /dev/sdb hdd 300G Yes 10s ago
Ceph-203 /dev/sdc hdd 500G Yes 10s ago
Ceph-203 /dev/sdd hdd 1024G Yes 10s ago
Ceph-203 /dev/sr0 hdd VMware..xxx space (<5GB)
# 每个节点 3 块数据盘 × 3 个节点 = 9 个候选 OSD
============================
AVAILABLE 列的评判标准:就是"这块盘还能不能拿来当 OSD"
一旦加入OSD成功,Ceph 在上面建了 LVM、写了文件系统
再次查看时,AVAILABLE 从 Yes 变No --> ✅️ 不是盘坏了,是盘已经有主了
2)查看当前 OSD 列表(加盘前)
root@Ceph-201 ~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0 root default
# 空 ——> 还没加 OSD
| 字段 | 说明 |
|---|---|
| ID | OSD 或节点的唯一标识符,负数通常表示分组节点-1:默认根节点 |
| CLASS | 存储设备的类型分类 如 hdd(机械硬盘)、ssd(固态硬盘)、nvme(NVMe SSD) |
| WEIGHT | CRUSH 算法中使用的权重值,决定数据分布比例 容量越大权重通常越大 |
| TYPE | 节点类型 如 root(根节点)、host(主机)、osd(存储守护进程) |
| NAME | 节点名称 可能是主机名或 OSD 编号 |
| STATUS | 状态 up 表示在线可用,down 表示离线 |
| REWEIGHT | 临时权重调整值,用于控制数据迁移 1.0 为正常,0.0 为禁止数据 |
| PRI-AFF | Placement Group 亲和性设置 |
📌 CLASS 类型速查:
| CLASS | 接口/协议 | 判断依据 | 性能定位 | VMware 模拟 |
|---|---|---|---|---|
hdd(机械硬盘) |
SATA/SCSI | rotational=1,/dev/sd* |
慢,便宜,容量大 | SCSI/SATA 虚拟盘(默认) |
ssd(固态硬盘) |
SATA/SCSI | rotational=0,/dev/sd* |
快,适合热数据 | SCSI/NVMe 虚拟盘 |
nvme(NVMe SSD) |
PCIe 直连 | /dev/nvme*(自动识别) |
最快,延迟最低 | NVMe 虚拟盘 |
hdd < ssd < nvme — CRUSH 用 CLASS 区分快慢,实现数据分层
元数据放 nvme、热数据放 ssd、冷数据放 hdd
⭐批量添加 OSD
'一次一条命令,将 9 块盘全部添加为 OSD'
# --- Ceph-201 节点 ---
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdb
✅️ 太慢了,等等吧...
Created osd(s) 0 on host 'Ceph-201'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdc
Created osd(s) 1 on host 'Ceph-201'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdd
Created osd(s) 2 on host 'Ceph-201'
root@Ceph-202 ~# ceph orch daemon add osd Ceph-202:/dev/sdb
Error initializing cluster client: ObjectNotFound('RADOS object not found (error calling conf_read_file)')
# ↑ Ceph-202 本地找不到 /etc/ceph/ceph.conf,无法知道 Monitor 在哪,认证凭据也没有
🧱 通俗解释:
ceph orch host add(添加主机到集群) 只是把主机名和 IP 登记到集群的"花名册"上(Monitor 知道有这台机器了),但并没有把"身份证"发给这台机器执行
ceph orch daemon add osd时,命令要和 Monitor 通信——需要两样东西: -ceph.conf→ "公司在哪"(Monitor 地址) -ceph.client.admin.keyring→ "你是谁"(管理员身份证明)Ceph-202 本地没有这两个文件 → 报
ObjectNotFound解决:从 Ceph-201(引导节点)拷贝过去就行
📌 延伸 — 多集群管理:既然
ceph.conf+keyring决定了"连哪个集群、以什么身份连"那么一个客户端拿着多套配置文件,就能同时管理多个 Ceph 集群:
# 切换到集群 A
ceph --fsid <fsid-A> -c /etc/ceph/ceph-A.conf -k /etc/ceph/ceph-A.client.admin.keyring -s
# 切换到集群 B
ceph --fsid <fsid-B> -c /etc/ceph/ceph-B.conf -k /etc/ceph/ceph-B.client.admin.keyring -s
[!note]
无需登录到不同节点,在本地切换配置文件即可——类似于 kubectl 的 context 切换
'👇在 Ceph-201 上执行,把"身份证"分发到其他节点'
root@Ceph-201 ~# scp /etc/ceph/ceph.conf root@Ceph-202:/etc/ceph/
root@Ceph-201 ~# scp /etc/ceph/ceph.client.admin.keyring root@Ceph-202:/etc/ceph/
'👇设置正确权限'
root@Ceph-201 ~# ssh root@Ceph-202 "chmod 644 /etc/ceph/ceph.conf && chmod 600 /etc/ceph/ceph.client.admin.keyring"
# --- Ceph-202 节点 ---
root@Ceph-201 ~# ceph orch daemon add osd Ceph-202:/dev/sdb
Created osd(s) 3 on host 'Ceph-202'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-202:/dev/sdc
Created osd(s) 4 on host 'Ceph-202'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-202:/dev/sdd
Created osd(s) 5 on host 'Ceph-202'
# --- Ceph-203 节点 ---
'同上'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-203:/dev/sdb
Created osd(s) 6 on host 'Ceph-203'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-203:/dev/sdc
Created osd(s) 7 on host 'Ceph-203'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-203:/dev/sdd
Created osd(s) 8 on host 'Ceph-203'
❤️LVM 技术栈
💡 底层原理:ceph 底层使用 LVM 技术栈 管理磁盘,每块盘会被初始化为 LVM PV → VG → LV
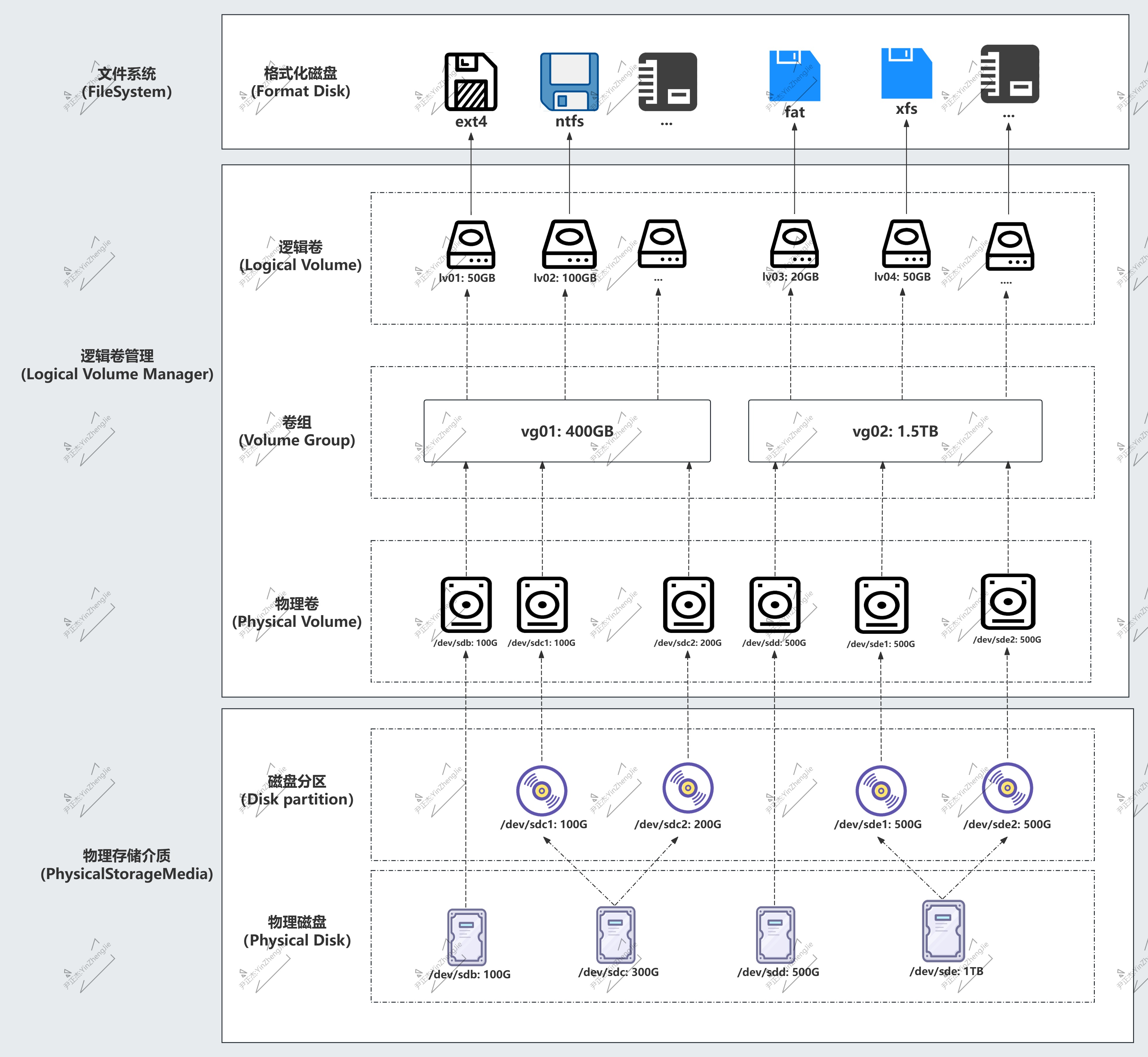
🧱 LVM 技术栈详解:PV → VG → LV
LVM(逻辑卷管理器)是 Linux 下对磁盘进行灵活分区管理的技术
它的核心思路是:在物理磁盘和文件系统之间加一层抽象
让你可以随时调整"分区"大小,而不需要像传统分区那样推倒重来
① 物理卷 — PV(Physical Volume)
PV 是最底层的存储单元
- PV 可以是一整块物理磁盘(如
/dev/sdb),也可以是磁盘上的一个分区(如/dev/sda3) - 一块盘/分区被
pvcreate标记后,LVM 就能识别并使用它 - PV 内部被切分为固定大小的 PE(Physical Extent,默认 4MB)
- PE 是 LVM 分配空间的最小单位
📌 类比:PV 就像一块空地——不管原来是整座山(整块盘)还是山的一角(分区),圈进来之后就都是可用的地皮
② 卷组 — VG(Volume Group)
VG 是 LVM 的"资源池"——把多块 PV 整合成一个统一的大池子
- 多个 PV 可以加入同一个 VG,VG 的容量 = 所有 PV 容量之和
- VG 就像一个弹性仓库——你只负责从池子里取空间,底层是哪块盘不用操心
- 后期可以随时往 VG 里加新盘(新 PV),也可以移除旧盘(数据迁移后)
📌 类比:VG 就像把多块空地合并成一个大工地
③ 逻辑卷 — LV(Logical Volume)
LV 是从 VG 中切分出来的、最终可用的存储空间
- 从 VG 中按需划分,大小可以动态调整(扩容/缩容)
- LV 可以像普通分区一样格式化(ext4/XFS)并挂载使用
- LV 支持快照(snapshot)——给某个 LV 拍一个"当时的状态",用于备份或回滚
📌 类比:LV 就像从大工地里隔出来的房间——想要多大隔多大,房间不够用了还能在线扩容
📋 三层结构速查表:
| 层次 | 英文 | 是什么 | 关键操作 |
|---|---|---|---|
| 物理卷 | PV | 底层存储"砖块" | pvcreate /dev/sdb |
| 卷组 | VG | 多块 PV 的"资源池" | vgcreate vg_name /dev/sdb /dev/sdc |
| 逻辑卷 | LV | 最终使用的"存储空间" | lvcreate -L 100G -n lv_name vg_name |
🔁 数据流向:物理磁盘 → PV → VG → LV → 格式化文件系统 → 挂载使用
⚖️ LVM 的优缺点:
| 优点 | 缺点 | |
|---|---|---|
| 1 | 在线扩容:LV 不够用了,在线扩,不影响正在跑的业务 | 多一层开销:比直接操作裸盘多一层抽象,有微弱性能损耗 |
| 2 | 灵活聚合:多块小盘合成一个大 VG,打破单盘容量限制 加新盘 → 扩 VG → 扩 LV → 文件系统变大 |
故障面扩大:VG 中某块 PV 坏了,用到它的 LV 会受影响 |
| 3 | 快照功能:给 LV 拍快照,备份/回滚/测试都很方便 | 学习成本:多了一套概念(PV→VG→LV),排错链路变长 |
| 4 | 动态伸缩:不光能扩容,还能缩容(ext4 支持,XFS 不支持缩容) | 固件限制:固件不认识 LVM,只认普通分区 所以 /boot 通常要单独分出来放在 LVM 外面 |
💻 Ubuntu 与 LVM:
Ubuntu 系统安装时如果勾选"使用 LVM",底层就是这样运作的——安装程序自动创建:
# Ubuntu 默认 LVM 结构(以 40G 系统盘为例)
/dev/sda3 → PV ──→ ubuntu-vg(VG)──→ ubuntu-lv(LV,挂载到 /)
│
└── LV 不会占满整个 VG,留一部分空闲
'不是空间浪费,是刻意的'
'留着以后给 / 根分区在线扩容用'
# 验证一下(Ubuntu环境里就有)
root@Ceph-201 ~# lsblk
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot ✅️'/boot只认普通分区'
└─sda3 8:3 0 '38G' 0 part
└─ubuntu--vg-ubuntu--lv 252:0 0 '30G' 0 'lvm' /
👆 '这一整行是逻辑卷(LV)' 'LVM技术栈'👆
📌 细节 --> 从sda3开始分
✅️ 38G 的 PV,LV 只用了 30G → 8G 空闲留在 VG 里
root@Ceph-201 ~# vgs
VG #PV #LV #SN Attr VSize VFree
ubuntu-vg 1 1 0 wz--n- 38.00g 8.00g
👆 '这才是卷组'
✅️ VFree = 8G ← 空闲空间,随时可以扩给 /
📌 Ubuntu 不会一开始就把所有空间分给根分区,只会分一半左右——剩下的留在 VG 里
- 方便后续
lvextend在线扩容,不用重装系统
🔗 回到 Ceph:
Ceph 添加 OSD 时,ceph orch daemon add osd 在背后做的事本质上就是这套 LVM 流程:
# 当你执行 ceph orch daemon add osd Ceph-201:/dev/sdb 时,Ceph 自动:
/dev/sdb → pvcreate → 创建 PV
→ vgcreate → 创建 VG(名:ceph-<VG_UUID>)
→ lvcreate → 创建 LV(不进行文件系统格式化, BlueStore 直接写裸 LV)
✅️ BlueStore: '不依赖任何文件系统,直接在裸盘上存储'
root@Ceph-201 ~# vgs
VG #PV #LV #SN Attr VSize VFree
ceph-023d...f772 1 1 0 wz--n- <500.00g 0
ceph-6f9f...7035 1 1 0 wz--n- <1024.00g 0
ceph-fadf...ac73 1 1 0 wz--n- <300.00g 0
ubuntu-vg 1 1 0 wz--n- <38.00g <8.00g
# 👆 卷组名 = ceph-<VG_UUID>(VG_UUID 是 LVM 随机生成的)
'在 Ceph-202 上验证 LVM 结构'
root@Ceph-202 ~# lsblk
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 38G 0 part
└─ubuntu--vg-ubuntu--lv 252:0 0 30G 0 lvm /
'上面是系统盘'
sdb ✅️物理磁盘 'PV' 8:16 0 300G 0 disk
└─ceph--fadf...ac73-osd--block--2078...bd8bd 252:1 0 300G 0 lvm
sdc ✅️物理磁盘 'PV' 8:32 0 500G 0 disk
└─ceph--023d...f772-osd--block--8bb5...f359 252:2 0 500G 0 lvm
sdd ✅️物理磁盘 'PV' 8:48 0 1T 0 disk
└─ceph--6f9f...7035-osd--block--da9a...7195 252:0 0 1024G 0 lvm
# 👆 lsblk 看到的是基于物理磁盘创建的 LV(逻辑卷)
'这些逻辑卷被用作 Ceph OSD 的数据存储'
📋 命名规律速查:
| 层级 | 命名格式 | 示例(以 sdb 300G 为例) |
|---|---|---|
| VG | ceph-<VG_UUID>随机生成的 |
ceph-fadf...ac73 |
| LV 短名 | osd-block-<OSD_FSID> |
osd-block-2078...bd8bd |
| LV 完整名(lsblk) | ceph--<VG_UUID>-osd--block--<OSD_FSID> |
ceph--fadf...ac73-osd--block--2078...bd8bd |
📌 规律:
ceph-开头 → VG(卷组),osd-block-开头 → LV 短名
- LV 完整名 = VG名 + LV短名,
lsblk里看到的就是这个完整名- LV 短名中的
osd-block-<OSD_FSID>= OSD 的 fsid(/var/lib/ceph/<集群>/osd.<N>/fsid)
/var/lib/ceph/
└── fdc2219c-5344-11f1-8042-000c2990a57e/ <-- '这是集群的 FSID'
├── cephadm.adad9831..xxx
├── osd.3 ✅️ OSD 目录
├── osd.4 ✅️ OSD 目录
├── osd.5 ✅️ OSD 目录
├── ...xxx
└── crash
root@Ceph-201 osd.0# pwd
/var/lib/ceph/<集群>/osd.0
'每个 OSD 有一个唯一的 fsid'
root@Ceph-201 osd.0# cat fsid
2078...bd8bd
| 对比 | Ubuntu 系统盘 LVM | Ceph OSD 数据盘 LVM |
|---|---|---|
| PV | /dev/sda3(分区) |
/dev/sdb(整块裸盘) |
| VG | ubuntu-vg |
ceph-<VG_UUID> |
| LV 短名 | ubuntu-lv |
osd-block-<OSD_FSID> |
| LV 完整名(lsblk) | ubuntu--vg-ubuntu--lv |
ceph--<VG_UUID>-osd--block--<OSD_FSID> |
| 文件系统 | ext4(建在 LV 上) | 无(BlueStore 绕过文件系统直接操作裸 LV) |
| 扩容方式 | lvextend + resize2fs |
不需要——Ceph 已占满整块盘 |
📌 一句话:Ceph 底层使用 LVM 技术栈管理每块 OSD 数据盘
PV→VG→LV 三步把裸盘变成 Ceph 可管理的存储单元
BlueStore 直接在 LV 上读写,省掉了文件系统这层中间商
验证 OSD 状态
1)查看 OSD 树
root@Ceph-201 ~# ceph osd tree
'每个字段的含义,参考上面的表格'
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 5.34389 root default
-3 1.78130 host Ceph-201
0 hdd 0.29300 osd.0 up 1.00000 1.00000
1 hdd 0.48830 osd.1 up 1.00000 1.00000
2 hdd 1.00000 osd.2 up 1.00000 1.00000
-5 1.78130 host Ceph-202
3 hdd 0.29300 osd.3 up 1.00000 1.00000
4 hdd 0.48830 osd.4 up 1.00000 1.00000
5 hdd 1.00000 osd.5 up 1.00000 1.00000
-7 1.78130 host Ceph-203
6 hdd 0.29300 osd.6 up 1.00000 1.00000
7 hdd 0.48830 osd.7 up 1.00000 1.00000
8 hdd 1.00000 osd.8 up 1.00000 1.00000
'hdd -->机械硬盘'
# 9 个 OSD 全部 up ✅️
2)查看集群健康状态
root@Ceph-201 ~# ceph -s
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_OK ✅️ 健康!
services:
mon: 3 daemons, quorum Ceph-201,Ceph-202,Ceph-203 (age 113m) [leader: Ceph-201]
mgr: Ceph-201.cxdvrq(active, since 5h), standbys: Ceph-202.xdeumk
osd: 9 osds: 9 up (since 37m), 9 in (since 39m) ✅️ 9 个全 up
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 249 MiB used, 5.3 TiB / 5.3 TiB avail ✅️ 总空间 5.3T
pgs: 1 active+clean
📌 集群关键数据:3 节点 × 3 盘 = 9 OSD,总容量 ~5.3 TiB,9/9 在线,状态 HEALTH_OK
OSD 的移除与磁盘清理
加盘的反向操作——当你需要撤掉某个 OSD 或重新部署时:
1)从集群中删除 OSD 守护进程
root@Ceph-201 ~# ceph orch daemon rm osd.0 --force
Removed osd.0 from host 'Ceph-201'
rm # 移除 OSD 守护进程(容器停止并被删除)
osd.0 # 表示OSD的ID编号
--force # 跳过确认提示,直接执行
2)擦除磁盘上的 Ceph 数据(恢复为空盘)
ceph orch device zap <主机名> <路径> [--force]
root@Ceph-201 ~# ceph orch device zap Ceph-201 /dev/sdb --force
zap successful for /dev/sdb on Ceph-201
zap # "清零"——销毁 Ceph 建的 LVM 卷、分区、文件系统
--force # 跳过确认提示
root@Ceph-201 ~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.78130 root default
-3 1.78130 host Ceph-201
0 hdd 0.29300 osd.0 'down' 1.00000 1.00000
'已经down掉了'
root@Ceph-201 ~# ceph orch device ls
Ceph-201 /dev/sdb hdd 300G 'Yes' ✅️ AVAILABLE为Yes --> 可以重新添加为OSD
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdb
Created osd(s) 3 on host 'Ceph-201'
root@Ceph-201 ~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.07430 root default
-3 2.07430 host Ceph-201
0 hdd 0.29300 'osd.0' down 0 1.00000
1 hdd 0.48830 'osd.1' up 1.00000 1.00000
2 hdd 1.00000 'osd.2' up 1.00000 1.00000
3 hdd 0.29300 'osd.3' up 1.00000 1.00000
root@Ceph-201 ~# ceph -s
cluster:
id: 3ca027a7-5400-11f1-a4e3-000c2990a57e
health: HEALTH_WARN ❌️
⚠️ 此时 `ceph -s` 出现 `1 stray daemon(s)` 告警
1 stray daemon(s) not managed by cephadm
# 一个流浪进程,不被cephadm管理了
services: xxx
osd: 4 osds: 3 up (since 61s), 3 in (since 42s)
'4 个 OSD 记录,但只有 3 个在线'
osd.0 → down(旧号,没人管了)
osd.3 → up (新盘,新 ID)
🧱 为什么会有 stray daemon❓️
ceph orch daemon rm osd.0 → 只删了编排器层(cephadm 视角)的容器进程
ceph orch device zap Ceph-201 /dev/sdb → 磁盘清空
但是!CRUSH 拓扑层(CRUSH 全局视角)还记着 osd.0:
→ CRUSH 说:"osd.0 应该在线啊,去哪了?"
→ cephadm 说:"osd.0 不归我管了"
→ 这个没人认领的 OSD 就是 stray daemon(流浪进程)
| 层面 | 命令入口 | 管的 | 视角 |
|---|---|---|---|
| CRUSH 拓扑层 | ceph osd ... |
CRUSH 地图、OSD 状态、数据放置规则 | CRUSH 全局视角——"数据该往哪放" |
| 编排器层 | ceph orch ... |
容器/进程、磁盘设备、主机节点 | cephadm 视角——"服务跑在哪" |
📌 stray daemon 的根因:
ceph orch daemon rm只清了编排器层,CRUSH 拓扑层还记着这个 OSD → 两层不一致 → 集群告警✅ 正确做法:用
ceph orch osd rm一条命令同时清两层(停进程 + 清 CRUSH + 可选 zap),详见 day03 笔记
🔧 如果已经出现 stray daemon,此时 OSD 已经是 down 状态,直接 purge 就行:
'从 CRUSH 表彻底删除 → 集群名单踢出'
ceph osd purge osd.<旧ID> --yes-i-really-mean-it
# stray daemon 的 OSD 已经 down 了(容器早就被 rm 了),所以直接 purge 不会报错
root@Ceph-201 ~# ceph -s
cluster:
id: 3ca027a7-5400-11f1-a4e3-000c2990a57e
health: HEALTH_OK
services:...xxx
osd: 3 osds: 3 up (since 3m), 3 in (since 6m)
'三个osd,三个都在运行'
🔹 osd out 是什么?
`osd out` 的作用是 标记 OSD 为"即将退役"
触发 PG 恢复——集群自动把该 OSD 上的数据副本搬到其他 OSD,等数据全部搬完后再删盘就不会丢数据
============================
osd out 之后发生的事:
osd.3 上的副本 → 搬到 osd.1 / osd.2 / osd.4 ...
PG 状态:recovering → active+clean
数据搬完了 → 删 osd.3 就安全了
⚠️ 但实验环境几乎没数据,
osd out反而触发无意义的恢复
- 集群拼命搬空气,搬完你又加回来,纯属折腾
✅ 删除 OSD — 生产环境 vs 实验环境:
'============================='
' 生产环境(有真实数据)— 四步 '
'============================='
1)标记退役 → 触发 PG 恢复,数据安全搬到其他 OSD
root@Ceph-201 ~# ceph osd out osd.3
'等待 recovery 完成'
# ceph -s 确认 PG 全部 active+clean
'============================='
' 实验环境(没数据)— 三步即可 '
'============================='
📌 下篇笔记📚有更简单的方法
`ceph orch osd rm` ——> 一条命令完成停进程 + 清 CRUSH + 清磁盘
2)停进程
root@Ceph-201 ~# ceph orch daemon rm osd.3 --force
3)销户口
root@Ceph-201 ~# ceph osd purge osd.3 --yes-i-really-mean-it
4)清磁盘
root@Ceph-201 ~# ceph orch device zap Ceph-201 /dev/sdb --force
对比:
生产环境:out → daemon rm → purge → zap (多一步 out,保证数据安全)
实验环境: daemon rm → purge → zap (跳过 out,避免无意义恢复)
==============================
关键依赖:无论哪种,purge 都必须在 daemon rm 之后(要求 down 状态)
- ⚠️ zap 不可逆,生产环境慎用;实验环境无所谓
- 拍快照, 尝试单机部署
五、CRUSH 规则与故障域
🧱 故障域概念:Ceph 的 CRUSH 算法决定了数据副本如何分布在不同的 OSD 上,而"故障域"定义了故障的隔离边界
默认情况下,Ceph 按主机(host)划分故障域
- 这意味着 CRUSH 会尽量将同一数据的多个副本放置在不同的主机上
默认规则长什么样❓️
root@Ceph-201 ~# ceph osd crush rule dump
'查看Ceph集群中的所有CRUSH规则'
[
{
"rule_id": 0, <-- 默认规则 ✅️
"rule_name": "replicated_rule",
"type": 1,
"steps": [
{ "op": "take", "item": -1, "item_name": "default" },
{ "op": "chooseleaf_firstn", "num": 0, "type": "host" },
{ "op": "emit" }
]
}
]
📌 chooseleaf_firstn + type: "host" 的执行步骤(假设副本数 = 3):
① take default → 从 CRUSH 树的根节点开始
② chooseleaf_firstn → 选 N 台不同的 host,每台 host 下再挑 1 块最佳 OSD
num = 0 → 这里的 0 不是"选 0 个",是"不硬编码"的占位符
→ 实际 N 从存储池的 size 参数动态读取
→ 池 size=3 → 0 等价于 3(如果池 size=2,0 就等价于 2)
Step 1: 选第 1 台 host → 挑该 host 下的一块 OSD → 放副本①
Step 2: 选第 2 台 host(必须和 Step1 不同)→ 挑 OSD → 放副本②
Step 3: 选第 3 台 host(必须和 Step1/2 不同)→ 挑 OSD → 放副本③
核心约束:同一台 host 只能被选中一次!
💡 num = 0 的设计意图:让一条 CRUSH 规则能被多个不同副本数的池复用——规则本身不写死数量,而是从池的 size 参数动态读取
num 如果写死成 3,那这条规则就只能给 size=3 的池用,其他池得另建规则
单节点 + 默认规则 = 矛盾
你的单节点 CRUSH 树:
root default
└─ host Ceph-201 ← 只有 1 台主机!
├─ osd.0 (sdb)
├─ osd.1 (sdc)
└─ osd.2 (sdd)
CRUSH 尝试放置 3 个副本的过程:
选第 1 台 host → Ceph-201 → 挑 osd.0 → 放副本① ✅
选第 2 台 host → 树里只有 Ceph-201,但它已被选过 → 不能再选 → 失败 ❌
选第 3 台 host → 同上 → 失败 ❌
最终结果:3 个副本只放下了 1 个
"只能选 1 块盘"这句话的真正含义:
你有 3 块盘(sdb、sdc、sdd),盘是够的
但 CRUSH 规则的第一关不是"找盘",而是"找不同的主机"
每台主机只能被选一次,1 台主机 → 只能过第一关一次 → 只能选到 1 块盘
- 3 块盘 ≠❌️ 3 个副本存放位置
- 3 台主机 =✅️ 3 个副本存放位置 ← CRUSH 要的是这个
单节点 HEALTH_WARN 复现
'主要是在单节点下进行添加OSD设备'
# 我这里是进行了恢复快照
root@Ceph-201 ~# ceph orch host ls
HOST ADDR LABELS STATUS
Ceph-201 10.0.0.201 _admin
1 hosts in cluster
'不把其他两台主机添加到集群' <-- 它俩关机状态
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdb
Created osd(s) 0 on host 'Ceph-201'
# 然后直接添加OSD设备
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdc
Created osd(s) 1 on host 'Ceph-201'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdd
Created osd(s) 2 on host 'Ceph-201'
root@Ceph-201 ~# ceph -s
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_OK
'在我添加完, 立马查看状态 ✅️ OK'
可是并没有看到 HEALTH_WARN ❌️
⚠️ 加完 3 块 OSD 立刻 ceph -s 看到 HEALTH_OK,是因为 PG 还没完成创建/peering
实测等一会儿再查,状态就变换了❌️,不是版本差异,纯粹是时序问题
root@Ceph-201 ~# ceph -s
cluster:
id: fdc2219c-5344-11f1-8042-000c2990a57e
health: HEALTH_WARN ❌️ "告警暴露出来了"
Reduced data availability: 1 pg inactive --> 'PG 不活跃'
Degraded data redundancy: 1 pg undersized --> '副本数不足'
# 要 3 个只放了 1 个
root@Ceph-201 ~# ceph osd pool ls detail
'显示集群中所有存储池的详细配置信息'
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0...
replicated size 3 # 副本数=3 → 要放 3 份
min_size 2 # 最少 2 个副本才允许读写I/O
crush_rule 0 # crush_rule 0 = 默认规则 (type = host)
📌 只有 1 台主机 → CRUSH 只能选出 1 块盘 → PG undersized '副本数不足'
创建以 OSD 为故障域的规则
| 命令 | 作用 | 一句话 |
|---|---|---|
ceph osd crush rule ls |
列出所有规则 只列名字 |
"有哪些规则" |
ceph osd crush rule dump <规则名> |
查看规则内部细节 完整 JSON |
"这条规则内部长什么样" |
ceph osd crush rule create-replicated <规则名> <根节点> <故障域> |
创建副本规则 | "起名 + 定根 + 定故障域,三步搞定" |
ceph osd crush rule create-erasure <规则名> <profile名> |
创建纠删码规则 | "引用 profile,让规则知道 k/m 和编码算法" |
| 对比维度 | 副本规则 create-replicated |
纠删码规则 create-erasure |
|---|---|---|
| 参数 | 规则名 + 根节点 + 故障域 | 规则名 + 纠删码 profile |
| 故障域在哪指定 | 命令里直接写(host / osd / rack) | 不在命令里——profile 已声明 k+m,CRUSH 据此选盘 |
| 为什么不同 | 副本 = 简单 copy,不需要额外配置 | 纠删码要提前定义 k+m 比例、编码算法(jerasure / lrc 等),这些全在 profile 里 |
root@Ceph-201 ~# ceph osd crush rule ls
replicated_rule ← 默认,type = host
1)创建新规则(故障域从 host 降为 osd)
'语法:ceph osd crush rule create-replicated <规则名> <根节点> <故障域级别>'
root@ceph:~# ceph osd crush rule create-replicated rule_osd default osd
root@ceph:~# ceph osd crush rule ls
replicated_rule ← 默认,type = host
rule_osd ← 新建,type = osd
2)对比两条规则
root@ceph:~# ceph osd crush rule dump rule_osd
'指定查看我们刚创建的规则 rule_osd'
# dump后面紧跟规则名
{
"rule_id": 1, <-- 新建规则 ✅️
"rule_name": "rule_osd",
"type": 1,
"steps": [
{ "op": "take", "item": -1, "item_name": "default" },
{ "op": "choose_firstn", "num": 0, "type": "osd" },
{ "op": "emit" }
]
}
📌 chooseleaf_firstn + host vs choose_firstn + osd:
type = host (chooseleaf_firstn) type = osd (choose_firstn)
① 先选 host,再在 host 下选 OSD ① 直接在 OSD 层选,不管 OSD 属于谁
② 同一 host 只能被选一次 ② 任何 OSD 都可以被独立选中
┌─────────────────────┐ ┌────────────────────┐
│ root │ │ root │
│ └─ host Ceph-201 │ │ ├─ osd.0 → 副本① │
│ ├─ osd.0 → 副本①| │ ├─ osd.1 → 副本② │
│ ├─ osd.1 ✗ | │ └─ osd.2 → 副本③ │
│ └─ osd.2 ✗ | │ │
│ │ │ 3 块盘都在同一台 │
│ 只能放 1 个副本 │ │ 主机上也没关系 │
└─────────────────────┘ └───────────────────┘
关联存储池到新规则
ceph osd pool set <存储池名称> <参数名> <参数值>
# 将存储池关联到新规则
root@Ceph-201 ~# ceph osd pool set .mgr crush_rule rule_osd
# rule_osd 我们新建的规则
set pool 1 crush_rule to rule_osd
===================================
`.mgr` 是什么❓️
1.Manager 守护进程的内部存储池,bootstrap(初始化集群) 时自动创建
2.Manager 用它来存设备健康+数据、性能指标、Dashboard 配置等"内部账本",不存用户数据
3.点号开头是命名惯例,表示"系统池"
4.集群启动后第一个池就是它——所以 单节点 HEALTH_WARN 也是它先暴露出来的
`Dashboard` 是什么❓️
1.就是 Ceph 自带的 Web 管理界面(端口 8443)
2.你浏览器打开后能看集群健康状态、OSD列表、性能图表、存储池信息等等
✅️ Dashboard 配置存在 .mgr 池里指的是
1.你通过 Web 界面做的设置(比如改了登录密码、调了监控告警阈值)
2.Manager进程把这些配置数据写到 .mgr 池里持久化保存
3.这样即使 Manager 重启,配置也不会丢
root@Ceph-201 ~# ceph osd pool ls detail
'显示集群中所有存储池的详细配置信息'
pool 1 '.mgr' ... crush_rule 1 ...
✅️ rule_id 从 0 变成 1
# 由默认规则 --> 到新建规则
root@Ceph-201 ~# ceph -s
cluster:
health: HEALTH_OK ✅️
...
pgs: 1 active+clean 🏷️
场景速查表
| 场景 | 故障域 | 副本数 | CRUSH 规则 | 结果 |
|---|---|---|---|---|
| 多节点(≥3 台) | host | 3 | chooseleaf_firstn + host |
✅ HEALTH_OK |
| 单节点 + 默认规则 | host | 3 | chooseleaf_firstn + host |
❌ PG undersized 副本数不足 |
| 单节点 + 手动改规则 | osd | 3 | choose_firstn + osd |
✅ HEALTH_OK |
单节点 + --single-host-defaults |
osd | 2 | choose_firstn + osd |
✅ HEALTH_OK |
🧱 一句话总结:默认 CRUSH 规则 type=host 的本质是"同一个数据的多个副本必须放在不同主机上"
- 宁可少放,也不能全堆在同一台主机(主机一挂所有副本全丢)
- 单节点实验要么用
--single-host-defaults,要么手动创建type=osd的规则
要在单个主机上部署 Ceph 集群,请在引导时使用
--single-host-defaults标志此类集群通常不适合生产环境**
该标志会自动设置以下配置选项:
global/osd_crush_chooseleaf_type = 0— 故障域从 host 降为 OSD 级别- 默认规则直接就是 osd 故障域,无需手动改
global/osd_pool_default_size = 2— 默认副本数从 3 降为 2mgr/mgr_standby_modules = False— 禁用备用 Manager 模块💡 参考文档:不同部署场景的推荐配置
集群删除(完整流程)
root@Ceph-201 ~# ceph orch device ls
'查看集群可用设备' --> 它们已经添加为OSD(已经被 Ceph 占用,不能再加第二次)
--> NO(不可用,不能再次添加了) Has a FileSystem(有了文件系统)
Ceph-201 /dev/sdb hdd 300G No❌️
Ceph-201 /dev/sdc hdd 500G No❌️
Ceph-201 /dev/sdd hdd 1024G No❌️
====================================
AVAILABLE = No 不是"坏了",是"已上岗" --> 表示磁盘上有 Ceph 数据
1)禁用 cephadm 模块(停止所有编排操作)
root@Ceph-201 ~# ceph mgr module disable cephadm
2)获取集群 FSID
root@Ceph-201 ~# ceph fsid
fdc2219c-5344-11f1-8042-000c2990a57e
3)在所有主机上清除 Ceph 守护程序和数据
'⚠️ 所有节点都要执行!'
root@Ceph-201 ~# cephadm rm-cluster --force --zap-osds --fsid fdc2219c-5344-11f1-8042-000c2990a57e
--force # 强制删除 --> "别问我确认,直接干"
--zap-osds # 清除磁盘上的 OSD 数据
--fsid fdcxxx # 指定FSID
Deleting cluster with fsid: fdc2219c-...xxx
Zapping /dev/sdb...
Zapping /dev/sdc...
Zapping /dev/sdd...
'初始化集群自动创建的文件也都删除了'
# No such file or directory
root@Ceph-201 ~# ls /etc/ceph/ceph.pub
# 到处分发的公钥
'都删除了'
root@Ceph-201 ~# ls /etc/ceph/ceph.conf
# 最小配置文件
root@Ceph-201 ~# ls /etc/ceph/ceph.client.admin.keyring
# 管理员密钥环
4)清理残留
root@Ceph-201 ~# ceph -s
Error initializing cluster client: ObjectNotFound(...) --> ✅️ 集群已不存在
root@Ceph-201 ~# rm -rf /etc/ceph/rbdmap
root@Ceph-201 ~# > /root/.ssh/authorized_keys
'清空 authorized_keys 文件,移除 cephadm bootstrap 写入的 SSH 公钥'
⚠️ 注意:
cephadm rm-cluster需要在所有集群节点上执行
--zap-osds会彻底清除磁盘上的所有 Ceph 数据- ☠️ 清空 OSD 盘上的所有数据
- ✅️ 不加 --zap-osds 还有救(盘上数据还在,重建 Monitor 就行)
- 参照下面👇重建集群
- 你要是想保留数据只重建 Monitor 不加 --zap-osds
手动指定集群 FSID
- 它只有一个场景:集群坏了要重建,但你不想丢数据
- 机器还在、盘还在、Ceph数据还在
正常装集群:cephadm bootstrap
└── 自动生成一个随机 FSID,OSD 盘上标记的就是这个 ID
'FSID 就是集群的"身份证号"'
root@Ceph-201 ~# ceph fsid
fdc2219c-5344-11f1-8042-000c2990a57e
# 获取当前FSID号
root@Ceph-201 ~# cephadm bootstrap --fsid fdc221...xxx
--fsid 用旧 ID → 磁盘上的 OSD 还认得这个 FSID,数据能恢复
单节点部署
'单节点 + --single-host-defaults'
1)设置主机名
root@Ceph-201 ~# tail -3 /etc/hosts
10.0.0.201 Ceph-201
10.0.0.202 Ceph-202
10.0.0.203 Ceph-203
2)使用 --single-host-defaults 重新引导
root@Ceph-201 ~# cephadm bootstrap \
--mon-ip 10.0.0.201 \
--single-host-defaults \
--initial-dashboard-password=Oldboy123.com \
--dashboard-password-noupdate \
--allow-fqdn-hostname \
--skip-pull
Ceph Dashboard is now available at:
URL: https://Ceph-201:8443/
User: admin
Password: Oldboy123.com
'单节点优化模式已生效'
3)查看默认 CRUSH 规则(故障域已是 osd 级别)
root@Ceph-201 ~# ceph osd crush rule dump replicated_rule
# dump后紧跟的是默认的规则名
{
"rule_id": 0, ✅️ 这个0也能说明它是默认的规则
"rule_name": "replicated_rule",
"type": 1,
"steps": [
{ "op": "take", "item": -1, "item_name": "default" },
{ "op": "choose_firstn", "num": 0, "type": "osd" }, <-- ✅️已经是 osd 级别
{ "op": "emit" }
]
}
4)逐个添加 OSD(也可逐个指定磁盘)
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdb
Created osd(s) 0 on host 'Ceph-201'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdc
Created osd(s) 1 on host 'Ceph-201'
root@Ceph-201 ~# ceph orch daemon add osd Ceph-201:/dev/sdd
Created osd(s) 2 on host 'Ceph-201'
root@Ceph-201 ~# ceph -s
cluster:
id: 3ca027a7-5400-11f1-a4e3-000c2990a57e
health: HEALTH_OK ✅️
services:
mon: 1 daemons, quorum Ceph-201 (age 49m) [leader: Ceph-201]
mgr: Ceph-201.ylifrh(active, since 47m), standbys: Ceph-201.eukksl
# 部署了两个 mgr
'一台机器上跑了两个 MGR 守护进程 ——> 一个 active,一个 standby'
osd: 3 osds: 3 up (since 39m), 3 in (since 39m)
5)验证最终状态
root@Ceph-201 ~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.78130 root default
-3 1.78130 host Ceph-201
0 hdd 0.29300 osd.0 up 1.00000 1.00000
1 hdd 0.48830 osd.1 up 1.00000 1.00000
2 hdd 1.00000 osd.2 up 1.00000 1.00000
root@Ceph-201 ~# ceph osd pool ls detail
pool 1 '.mgr' replicated size 2 min_size 1 crush_rule 0 ...
'副本数size 2, min_size 1' # --single-host-defaults 的效果
💡 推荐:实验/学习环境用 --single-host-defaults,生产环境严格多节点部署